고정 헤더 영역
상세 컨텐츠
본문
4.1.1 컨슈머와 컨슈머 그룹
애플리케이션에서 컨슈머 객체를 생성하고, 토픽을 구독하고, 메시지를 받아 검사하고 결과를 작성한다고 해보자.
만약 프로듀서가 애플리케이션이 검사할 수 있는 속도보다 더 빠른 속도로 토픽에 메시지를 쓰게 된다면 어떻게 될까?
만약 컨슈머가 단 한개뿐이라면 애플리케이션은 새로 추가되는 메시지의 속도를 따라잡을 수 없다!
프로듀서에서 빠른 속도로 브로커에 쓰여진 메시지는 계속해서 뒤로 밀리게 될 것이다.
따라서 우리는 토픽의 파티션들에 쓰여진 데이터를 소비하는 작업을 확장할 수 있어야 한다.
여러개의 프로듀서가 동일한 토픽에 메시지를 쓰듯이,
여러개의 컨슈머가 동일한 토픽에서 서로 다른 파티션의 메시지를 받는 것이다.
컨슈머 그룹

카프카의 주된 목표중 하나는 카프카 토픽에 쓰여진 데이터를 전체 조직 안에서 여러 용도로 사용할 수 있도록 만드는 것이였다.
이러기 위해선 애플리케이션이 각각이 컨슈머 그룹을 갖도록 해야한다.
카프카는 성능 저하 없이 많은 수의 컨슈머와 컨슈머 그룹으로 확장이 가능하다.
즉 1개이상의 토픽에 대해 모든 메시지를 받아야하는 애플리케이션 단위 별로 컨슈머 그룹을 생성한다.
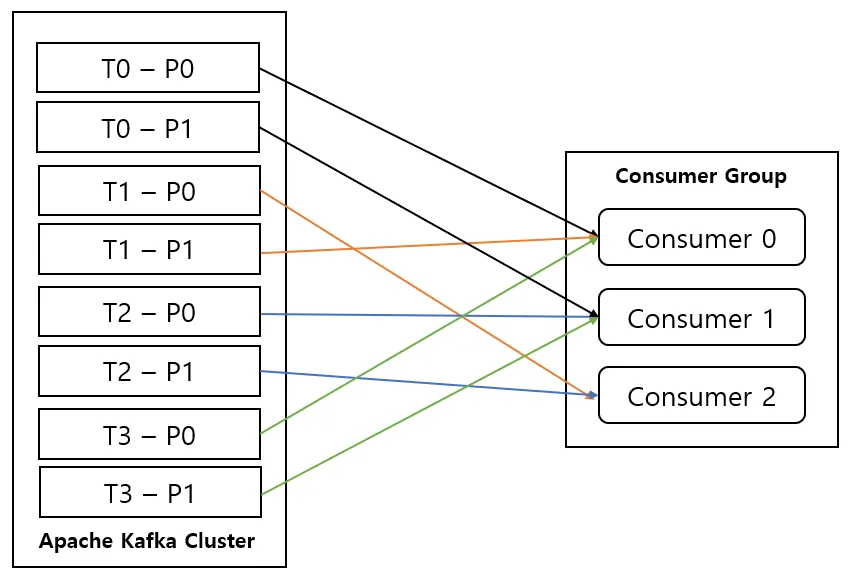
토픽에서 메시지를 읽거나 처리하는 규모를 확장하기 위해서는
이미 존재하는 컨슈머 그룹에 새로운 컨슈머를 추가함으로써 해당 그룹 내의 컨슈머 각각이 메시지의 일부만을 받아서 처리하도록 한다.
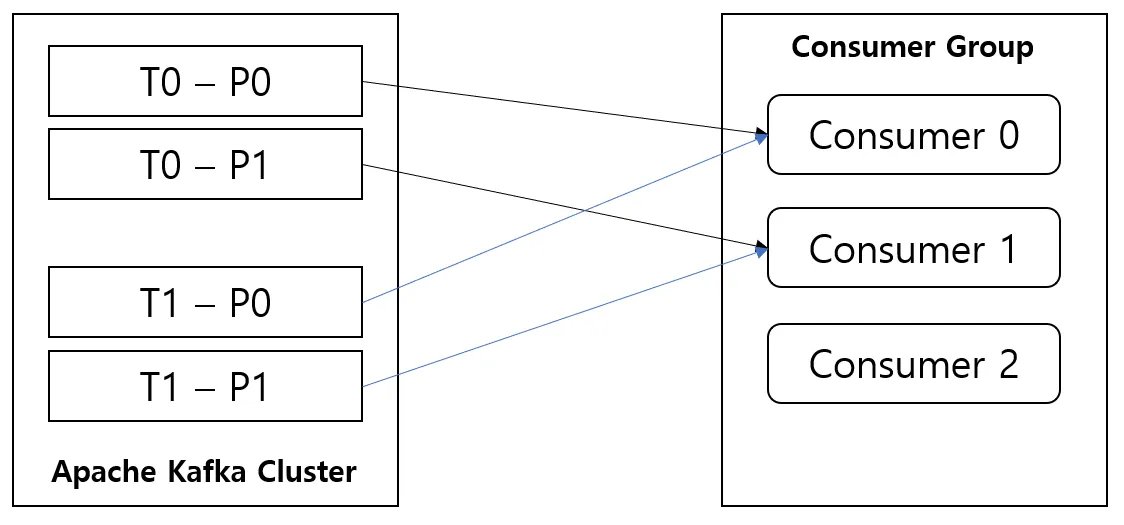
파티션 갯수와 컨슈머 갯수의 상관관계

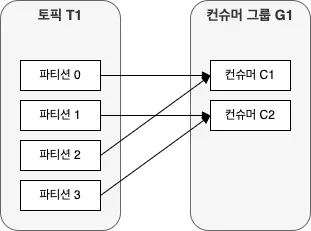

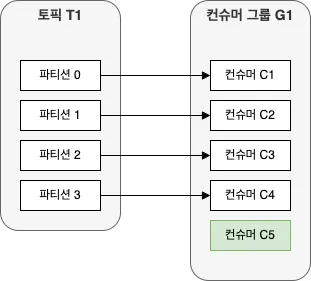
만약 하나의 토픽을 구독하는 하나의 컨슈머 그룹에 파티션 갯수보다 많은 컨슈머를 추가한다면,
컨슈머 중 몇몇은 유휴 상태가 되어 메시지를 전혀 받지 못한다! (마지막 이미지 참고)
이처럼 컨슈머 그룹에 컨슈머를 추가하는 것은, 카프카 토픽에서 읽어오는 데이터 양을 확장하는 주된 방법이다.
카프카 컨슈머가 지연 시간이 긴 작업 (DB 쓰기 등) 을 수행하는 것은 흔하다.
이런 경우 하나의 컨슈머로 토픽에 들어오는 데이터의 속도를 감당할 수 없기 때문에
컨슈머를 추가함으로써 단위 컨슈머가 처리하는 파티션과 메시지의 수를 분산시키는 것이 일반적인 규모확장 방식이다.
이것은 토픽을 생성할 때 파티션 수를 크게 잡아주는게 좋은 이유이기도 한데,
부하가 증가함에 따라서 더 많은 컨슈머를 추가할 수 있게 해주기 때문이다.
토픽에 설정된 파티션 수 이상으로 컨슈머를 투입하는 것이 아무 의미가 없다는 점을 명심해라!
컨슈머 그룹과 파티션 리밸런스
동일 컨슈머 그룹에 속한 컨슈머들은 토픽의 파티션들에 대한 소유권을 공유한다.
새로운 컨슈머가 그룹에 추가되면 이전에 다른 컨슈머가 읽고 있던 파니셥으로부터 메시지를 읽기 시작한다.
컨슈머가 종료되거나 크래시가 났을 경우, 구독중인 토픽이 변경되었을 때 (ex: 토픽에 새 파티션이 추가되었을때)에도
컨슈머에게 이러한 파티션 리밸런스가 진행된다.
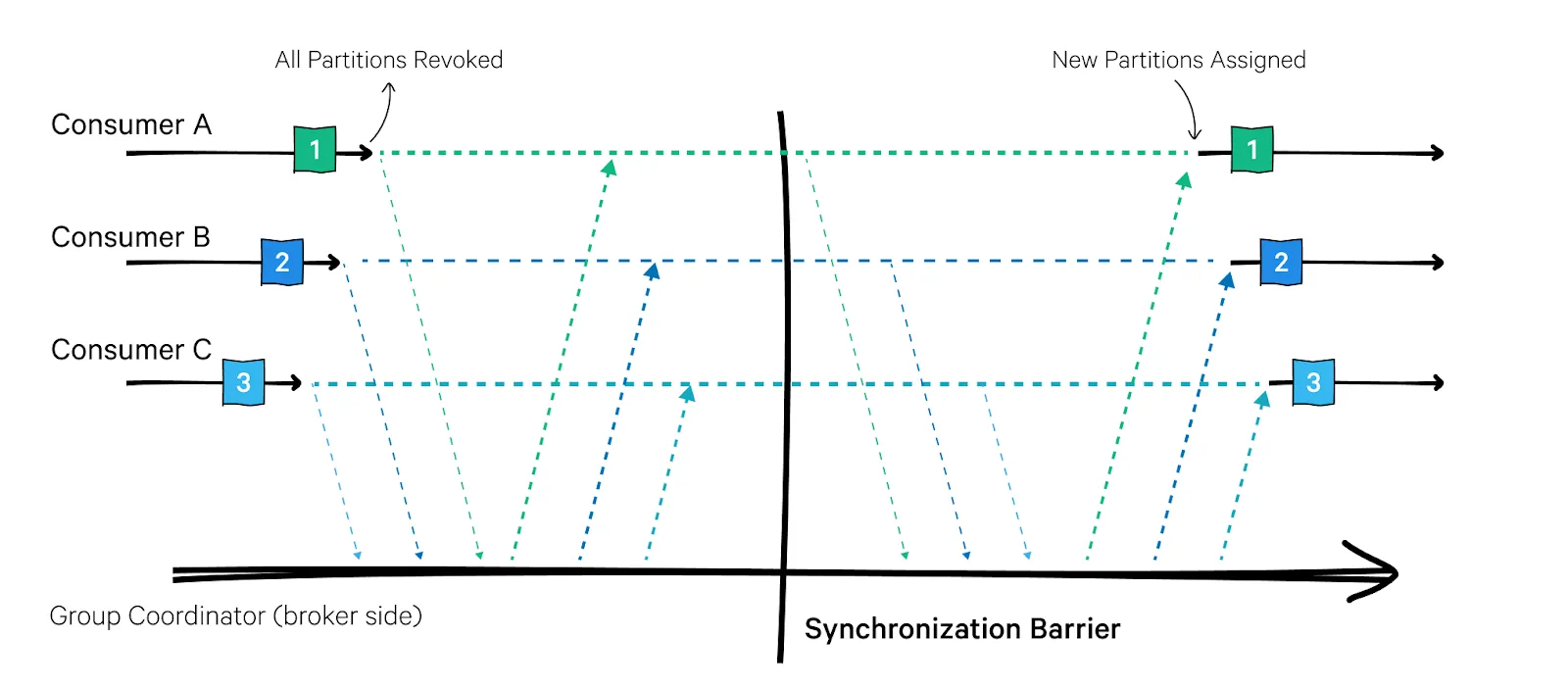
1. 조급한 리밸런스 (2.4버전부터 기본값)
모든 컨슈머는 읽기 작업을 멈추고 자신에 할당된 모든 파티션에 대한 소유권을 포기한 뒤,
컨슈머 그룹에 다시 참여하여 완전히 새로운 파티션 할당을 전달받는다.
이 방식은 컨슈머 그룹에 대해 짧은 시간 동안 작업을 멈추게 한다.
2. 협력적 리밸런스 (3.1버전부터 기본값)
한 컨슈머에게 할당된 파티션만을 다른 컨슈머에게 할당한다.
우선 컨슈머 그룹 리더가 다른 컨슈머들에게 각자에게 할당된 파티션 중 일부가 재할당될것이라고 통보
→ 컨슈머들은 해당 파티션에서 데이터 읽기를 멈추고 소유권을 포기
→ 컨슈머 그룹 리더가 이 포기된 파티션을 새로 할당함.
조급한 리밸런스처럼 전체 작업이 중단되는 사태듣 발생하지 않지만 점진적 작업이다보니 몇 번 반복될 수 있다.
이 특징은 리밸런싱 작업에 상당한 시간이 걸릴 위험이 있는 컨슈머 그룹에 속한 컨슈머 수가 많은 경우에 특히 중요하다.
컨슈머 그룹 내 리밸런싱 과정
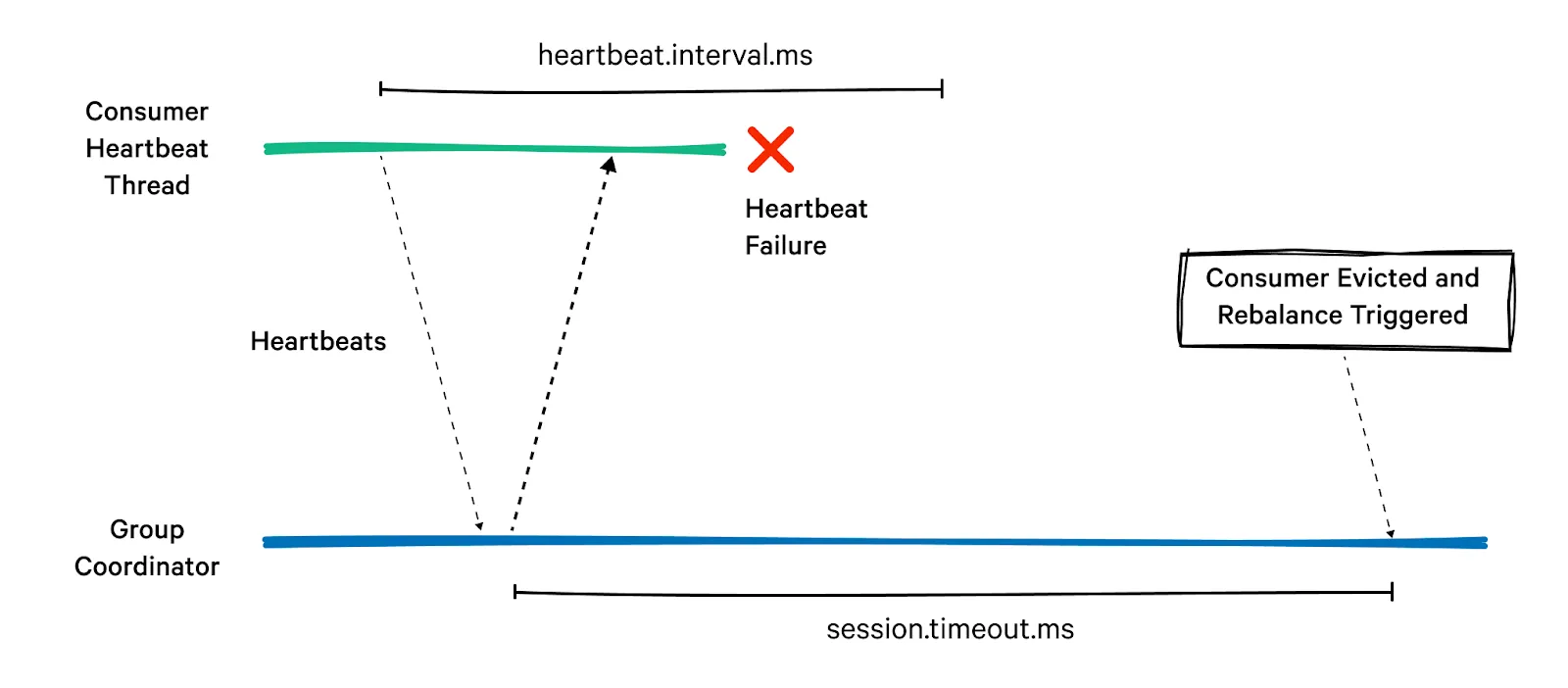
컨슈머는 해당 그룹의 그룹 코디네이터 역할을 지정받은 카프카 브로커에 하트비트를 전송하여
파티션에 대한 소유권을 유지한다.
(컨슈머 그룹 별로 이 그룹 코디네이터는 다를 수 있음)
만약 컨슈머가 일정 시간 이상 하트비트를 보내지 않는다면, 세션 타임아웃이 발생하면서
그룹 코디네이터는 해당 컨슈머가 죽었다고 간주하고 리밸런싱을 수행한다.
만약 컨슈머를 깔끔하게 닫아줄 경우, 컨슈머는 그룹 코디네이터에게 그룹을 나간다고 통지하는데,
그러면 그룹 코디네이터는 즉시 리밸런싱을 수행하여 처리가 정지되는 시간을 줄일 수 있다.
컨슈머 측 주요 설정들
정적 그룹 멤버십 (group.instance.id)
컨슈머가 꺼질 경우, 정적 그룹 멤버십 설정이 켜있으면, 자동으로 해당 컨슈머 그룹을 떠나지 않는다.
그리고 컨슈머가 다시 그룹에 조인하면, 멤버십이 그대로 유지되기 때문에,
리밸런스가 발생할 필요 없이 예전에 할당받았던 파티션들을 그대로 재할당받는다.
그룹 코디네이터는 그룹 내 각 멤버에 대한 파티션 할당을 캐시해두고 있기 때문에
정적 멤버가 다시 조인해 들어온다고 해서 리밸런싱을 발생시키지 않는다.
group.instance.id // 컨슈머에 고유한 값을 설정하면 컨슈머 그룹의 정적인 멤버가 되게 해줌.
정적 그룹 멤버십은 애플리케이션이 각 컨슈머에 할당된 파티션의 내용물을 사용해서
로컬 상태나 캐시를 유지해야 할 때 편리하다.
이러한 정적 그룹 멤버십에 속했던 파티션들은 재할당이 되지 않기 때문에, 해당 컨슈머가 재시작햇을 때 밀린 메시지들을 따라잡을 수 있는지 확인할 필요가 있다.
파티션 할당 전략 (partition.assignment.strategy)
PartitionAssignor 클래스는 컨슈머와 이들이 구독한 토픽들이 주어졌을 때,
어느 컨슈머에게 어느 파티션이 할당될지 결정하는 역할을 한다.
기본적으로, 카프카는 다음과 같은 파티션 할당 전략을 지원한다.
- Range
- 토픽 별로 Partition 순서대로 Consumer에게 할당된다.
- 가장 기본적인 할당 방식으로, 토픽 내의 파티션을 정렬한 후 컨슈머에게 연속적으로 할당하는 방식
- 컨슈머 수가 파티션 수보다 적으면 일부 컨슈머가 여러 개의 파티션을 가지게 됨
- 여러 개의 토픽을 구독하는 경우, 특정 컨슈머에게 특정 토픽이 몰릴 가능성 있음
partition.assignment.strategy=org.apache.kafka.clients.consumer.RangeAssignor

2. RoundRobin
- 모든 컨슈머에게 파티션을 균등하게 할당하는 방식
- 파티션을 컨슈머들에게 순차적으로 한 개씩 분배
- 토픽에 관계없이, partition 순서대로 consumer에 할당한다.
- 가장 공평한 방식, 특정 컨슈머에게 부하가 몰리는 것을 방지
✅ 여러 개의 토픽을 구독하는 경우에도 균등하게 분배 가능!
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
3. Sticky
- 기존 할당을 최대한 유지하면서 새로운 컨슈머가 추가되거나 제거될 때만 최소한의 재분배(Rebalance)를 수행
- 리밸런싱(Rebalancing) 최소화 → 중단 없이 안정적인 운영 가능
✅ 컨슈머가 추가되거나 제거될 때만 필요한 만큼의 재할당 발생
✅ 메시지 처리 중단 시간을 줄이고 성능을 높임
📌 예제
- 기존에 C1 → P0, P1, C2 → P2, P3, C3 → P4, P5였다고 가정
- 만약 C3가 제거되면 → C1과 C2가 P4, P5를 나눠 가짐
- 변경 최소화 → C1 → P0, P1, P4, C2 → P2, P3, P5
partition.assignment.strategy=org.apache.kafka.clients.consumer.StickyAssignor
4. Cooperative Sticky (Kafka 2.4 이상)
-
- StickyAssignor의 리밸런싱 최소화 특성과, 점진적인 할당 방식을 결합한 전략
- 기존 할당을 최대한 유지하면서 새로운 컨슈머가 참여할 때도 부드럽게 리밸런싱
- 리밸런스 시 모든 컨슈머가 한꺼번에 파티션을 반환하지 않고 일부만 반환한다!
최소한의 리밸런싱 + 일부만 반환하여 점진적으로 리밸런스
✅ 새로운 컨슈머 추가 시에도 중단 없이 안정적인 메시지 처리 가능
✅ StickyAssignor보다 더 부드러운 리밸런싱 제공
📌 예제
- 기존에 C1 → P0, P1, C2 → P2, P3, C3 → P4, P5
- 새로운 컨슈머 C4 추가 시 → 기존 컨슈머들이 모든 파티션을 반환하지 않고 일부만 반환
partition.assignment.strategy=org.apache.kafka.clients.consumer.CooperativeStickyAssignor
client.rack
기본적으로 컨슈머는 파티션의 리더 레플리카로부터 메시지를 읽어 온다.
하지만 클러스터가 다수의 데이터 센터 혹은 클라우드 가용 영역에 걸쳐 설치되어있는 경우
컨슈머와 같은 영역에 있는 레플리카의 메시지를 읽어 오는 것이 성능과 비용면에서 유리하다.
가장 가까운 레플리카로부터 읽어오려면 client.rack 설정을 잡아서
클라이언트가 위치한 영역을 식별하게 해줘야한다.
Kafka 브로커는 토픽의 리더 파티션을 특정 랙(Rack)에 있는 컨슈머에게 우선적으로 할당하여 데이터 전송 비용을 최소화 가능
즉, 같은 rack 값이 설정된 컨슈머는 동일한 랙에서 실행되는 브로커에서 데이터를 읽게 된다.
✅ 네트워크 트래픽 절감: 같은 데이터 센터 또는 가까운 지역에서 데이터를 읽음
✅ 지연 시간 감소: 원격 데이터 센터에서 데이터를 가져오는 대신 가까운 브로커에서 읽음
✅ 고가용성 보장: 여러 랙에 컨슈머가 분산될 경우 장애 발생 시에도 운영 가능
오프셋과 커밋
카프카에서 파티션에서의 현재 위치를 업데이트하는 작업을 오프셋 커밋이라고 한다.
파티션에서 성공적으로 처리해 낸 마지막 메시지를 커밋하여, 그 앞의 모든 메시지들 역시
성공적으로 처리했음을 암묵적으로 나타낸다.
Kafka에서 각 메시지는 특정 파티션에 저장되며, 오프셋도 파티션 단위로 설정된다.
즉, 오프셋은 특정 컨슈머 그룹이 특정 파티션에서 마지막으로 커밋한 위치를 의미한다.
🔹 컨슈머 그룹과 오프셋의 관계
오프셋은 단순히 "파티션 별로만 저장"되는 것이 아니라, 컨슈머 그룹별로 관리된다.
✅ 같은 그룹 ID를 가진 컨슈머들은 같은 오프셋을 공유하며, 리밸런싱 시 파티션이 다른 컨슈머에게 재할당될 수 있음.
(동일한 컨슈머 그룹)
✅ 다른 컨슈머 그룹은 같은 파티션을 소비하더라도, 오프셋을 독립적으로 관리함.
__consumer_offsets 토픽에 각 파티션 별로 커밋된 오프셋을 업데이트하도록 하는 메시지를 보냄으로써 오프셋 커밋이 이루어진다.
만약 컨슈머가 크래쉬되거나 새로운 컨슈머가 그룹에 추가될 경우 **“리밸런싱”**이 일어난다.
리밸런싱 이후 각 컨슈머는 리밸런스 이전에 처리하고 있던 파티션과 다른 파티션을 할당받을 수 있다.
이 때, 어디서부터 신규 파티션의 메시지를 읽어와야하는지 알아내기 위해
컨슈머는 각 파티션의 마지막으로 커밋된 메시지를 읽어온 뒤 거기서부터 처리를 재개한다.
📌 동기식 커밋 (Synchronous Commit)
- commitSync() 메서드를 사용하여 현재 오프셋을 즉시 커밋
- Kafka 브로커에 커밋 요청을 보내고 응답을 받을 때까지 블로킹됨(대기 상태)
- 요청이 실패하면 재시도하거나 예외 처리 가능
✅ 언제 사용해야 할까?
- 메시지 처리의 정확성이 중요한 경우
- 예: 금융 거래 시스템, 결제 시스템, 주문 처리 시스템
- 메시지 손실을 방지하고 정확하게 한 번(Exactly Once)만 처리해야 하는 경우
- 데이터 정합성이 중요한 경우
- 메시지를 중복 처리하면 안 되는 경우
- 장애 발생 시 중복 데이터를 방지하려면 동기식 커밋이 유리
- 컨슈머가 재시도 전략을 가지고 있는 경우
- 커밋이 실패하면 바로 예외를 던지고 적절한 처리를 수행 가능
✅ 장점
✔ 데이터 손실 방지: 커밋이 성공해야만 다음 메시지를 읽음
✔ 정확한 오프셋 관리: 중복 메시지 처리 가능성이 낮음
❌ 단점
❌ 성능 저하 가능: Kafka 브로커 응답을 기다려야 하므로 속도가 느려질 수 있음
❌ 네트워크 지연 발생 가능: 높은 TPS(초당 트랜잭션) 환경에서는 병목이 발생할 가능성이 있음
수동 커밋의 경우 브로커가 커밋 요청에 응답할 때 까지 애플리케이션이 블록된다.
즉, 애플리케이션의 처리량이 제한되므로 이럴 경우 비동기식 커밋을 사용하는 것이 좋다.
📌 동기식 커밋 예시 : Kafka Consumer 코드 (Spring Boot)
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.listener.AcknowledgingMessageListener;
import org.springframework.kafka.listener.ConsumerAwareListenerErrorHandler;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Service;
@Service
public class KafkaConsumerService {
@KafkaListener(
topics = "${kafka.topic.name}",
groupId = "${kafka.consumer.group-id}",
containerFactory = "kafkaListenerContainerFactory",
errorHandler = "customErrorHandler"
)
public void consume(
@Payload String message,
ConsumerRecord<?, ?> record,
Acknowledgment acknowledgment
) {
try {
// 1️⃣ 메시지 처리 로직
System.out.println("Consumed message: " + message);
// 2️⃣ 처리 성공 후 오프셋 커밋 (동기식 커밋)
acknowledgment.acknowledge();
} catch (Exception e) {
System.err.println("Message processing failed: " + e.getMessage());
// 예외 발생 시 커밋하지 않음 (재처리 가능)
}
}
}
📌 동기식 커밋 예시 : 커스텀 예외 처리 핸들러 (콜백 메서드)
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.listener.ConsumerAwareListenerErrorHandler;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
@Component("customErrorHandler")
public class CustomKafkaErrorHandler implements ConsumerAwareListenerErrorHandler {
@Override
public Object handleError(Message<?> message, ListenerExecutionFailedException exception, Consumer<?, ?> consumer) {
// 1️⃣ 에러 로그 출력
System.err.println("Error consuming message: " + message.getPayload());
System.err.println("Error: " + exception.getMessage());
// 2️⃣ 필요 시 특정 파티션의 오프셋을 수동 조정
consumer.seek(new org.apache.kafka.common.TopicPartition("your-topic", 0), 0);
return null; // 기본 재시도 정책 따름
}
}
📌 비동기식 커밋 (Asynchronous Commit)
- commitAsync() 메서드를 사용하여 커밋 요청을 비동기적으로 보냄
- Kafka 브로커 응답을 기다리지 않고 바로 다음 처리를 수행
- 콜백(callback) 메서드를 사용하여 커밋 성공 여부를 확인 가능
- 동기식 커밋의 경우 실패할 경우 재시도하는 반면,비동기식 커밋은 재시도할 수 없다.
=> 서버로부터 응답을 받은 시점에는 이미 다른 커밋 시도가 성공했을 수 있기 때문에 메시지 순서가 꼬여버릴 수 있다.
✅ 언제 사용해야 할까?
- 성능이 중요한 경우
- 예: 로그 수집 시스템, 메트릭 수집 시스템, 실시간 스트리밍 데이터 처리
- 메시지 손실이 발생해도 큰 문제가 되지 않는 경우
- TPS(초당 트랜잭션 수)가 높은 경우
- 빠른 처리가 필요한 경우 동기식 커밋보다 비동기식 커밋이 성능적으로 유리
- 일괄 처리(batch processing)에서 적절한 재시도 로직이 있는 경우
- 커밋 실패 시, 재시도하거나 보정 처리가 가능하다면 사용 가능
✅ 장점
✔ 성능 향상: 커밋 요청이 비동기적으로 처리되므로 속도가 빠름
✔ 처리량 증가 가능: Kafka 브로커 응답을 기다리지 않으므로 병목이 줄어듦
❌ 단점
❌ 데이터 손실 가능성: 커밋이 실패하면 메시지가 중복 처리되거나 손실될 가능성이 있음
❌ 중복 처리 발생 가능성: 컨슈머가 장애가 발생하면 일부 메시지가 중복 소비될 수 있음
📌 동기식 커밋 예시 : Kafka Consumer 코드 (Spring Boot)
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.listener.Acknowledgment;
import org.springframework.stereotype.Service;
import java.util.Collections;
import java.util.Map;
@Service
public class KafkaAsyncConsumerService {
@KafkaListener(topics = "my-topic", groupId = "my-group", containerFactory = "kafkaListenerContainerFactory")
public void consume(ConsumerRecord<String, String> record, Acknowledgment acknowledgment, Consumer<?, ?> consumer) {
try {
// 1️⃣ 메시지 처리
System.out.println("Consumed message: " + record.value());
// 2️⃣ 현재 메시지의 오프셋 정보 가져오기
TopicPartition partition = new TopicPartition(record.topic(), record.partition());
OffsetAndMetadata offset = new OffsetAndMetadata(record.offset() + 1, null);
// 3️⃣ 비동기 커밋 수행
consumer.commitAsync(Collections.singletonMap(partition, offset), new KafkaCommitCallback());
} catch (Exception e) {
System.err.println("Message processing failed: " + e.getMessage());
}
}
}
📌 비동기식 커밋 예시 : Kafka Consumer 코드 (Spring Boot)
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.clients.consumer.OffsetCommitCallback;
import java.util.Map;
public class KafkaCommitCallback implements OffsetCommitCallback {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception == null) {
// 커밋 성공 시 로그 출력
System.out.println("✅ Async commit successful: " + offsets);
} else {
// 커밋 실패 시 로그 출력 및 재시도 로직 추가 가능
System.err.println("❌ Async commit failed: " + exception.getMessage());
}
}
}
📌 공통 : Kafka 설정 파일 (application.yml)
kafka:
topic:
name: my-topic
consumer:
group-id: my-consumer-group
enable-auto-commit: false # 오프셋 자동 커밋 비활성화
auto-offset-reset: latest
📌 공통 : Kafka 컨테이너 팩토리 설정 (KafkaConfig.java)
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class KafkaConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-consumer-group");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 자동 커밋 비활성화
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setAckMode(org.springframework.kafka.listener.ContainerProperties.AckMode.MANUAL); // 수동 커밋
return factory;
}
}'프로그래밍 > kafka' 카테고리의 다른 글
| [카프카 핵심 가이드] 1,2,3장 : 카프카 기본 개념, 브로커, 프로듀서 (1) | 2025.02.06 |
|---|





댓글 영역