고정 헤더 영역
상세 컨텐츠
본문
📌 1.2 카프카 입문
카프카는 메시지 발행/구독 시스템이다.
분산 커밋 로그, 분산 스트리밍 플랫폼이라고 불리기도 한다.
파일 시스템이나 데이터베이스 커밋 로그는 모든 트랜잭션 기록을 지속성있게 보관함으로써,
시스템의 상태를 일관성있게 복구할 수 있도록 고안되었다.
이와 유사하게, 카프카에 저장된 데이터는
순서를 유지한 채로 지속성 있게 보관되며 결정적으로 읽을 수 있다.
또한 확장시 성능을 향상시키고 실패가 발생하더라도,
데이터 사용에는 문제가 없도록 시스템 안에서 데이터를 분산시켜 저장할 수 있다.
📌 1.2.1 메시지와 배치
카프카에서 데이터의 기본 단위는 메시지다. (바이트의 배열)
메시지는 키를 가질 수 있고, 이 키는 메시지를 저장할 파티션을 결정할 때 사용된다. (파티션 키로 동작)
같은 키를 가진 메시지는 파티션 수가 변하지 않는 한, 항상 같은 파티션에 저장된다.

카프카는 효율성을 위해 메시지를 배치 단위로 저장한다.
배치는 같은 토픽 파티션에 쓰여지는 메시지들의 집합이다.
메시지 하나하나를 쓸 때마다 네트워크를 오가는 오버헤드를 줄이기 위해 배치를 사용한다.
📌 1.2.3 토픽과 파티션
카프카에 저장되는 메시지는 토픽 단위로 분류된다.
토픽은 데이터베이스의 테이블이나 파일시스템의 폴더로 비유할 수 있다.
토픽은 다시 여러 개의 파티션으로 나눠진다.
커밋 로그의 관점으로 보면, 파티션은 하나의 로그에 해당한다.
파티션에 메시지가 쓰여질 땐 추가만 가능하다. (Append-only)
토픽 안의 메시지 전체에 대해 순서는 보장되지 않으며,
단일 파티션 안에서만 순서가 보장된다.
각 파티션이 서로 다른 서버에 저장될 수 있기 때문에,
하나의 토픽이 여러 개의 서버로 수평적으로 확장되어 하나의 서버의 용량을 넘어가는 성능을 보여줄 수 있다.
또 파티션은 복제될 수 있는데,
서로 다른 서버들이 동일한 파티션의 복제본을 저장하고 있기 때문에
서버 중 하나가 장애가 발생해도 읽거나 쓸 수 없는 상황이 벌어지지 않는다.
아래 그림 예시를 보자!

토픽 Foo, Bar가 존재하고, replicas가 3이여서 3개의 브로커에서 복제하여 데이터를 저장한다.
Foo, Bar 토픽은 각각 3개의 파티션으로 저장되고,
파티션 리더를 제외한 다른 브로커에 해당 파티션의 복제본을 저장한다.
위 그림에서 예를 들면,
Foo 토픽의 P1 파티션은 Broker 1번에서 파티션 리더를 맡는다.
해당 파티션은 Broker 2, Broker 3에 파티션 팔로워로 복제된다.
이후 파티션 리더를 갖고 있던 브로커가 장애가 발생하면, 다른 브로커에 있는 파티션을 대체하여 읽기를 지속해서 수행할 수 있다.
📌 1.2.4 프로듀서와 컨슈머
카프카 클라이언트는 이 시스템의 사용자이며, 기본적으로 컨슈머와 프로듀서가 있다.
그 외 데이터 통합에 사용되는 카프카 커넥트, 스트림 처리에 사용되는 카프카 스트림즈가 있다.
프로듀서는 새로운 메시지를 생성하고, 발행자, 작성자라고 부른다.
메시지는 특정 토픽에 쓰여지며,
프로듀서는 메시지를 쓸 때 토픽에 속한 특정 파티션을 지정해서 메시지를 쓰기도 한다.
이 파티션을 지정하는 로직은 파티셔너를 사용하여 구현할 수 있다.
컨슈머는 메시지를 읽고 구독자, 독자라고도 한다.
컨슈머는 1개 이상의 토픽을 구독해서 각 파티션에 쓰여진 순서대로 읽어온다.
컨슈머는 메시지에 오프셋을 기록함으로써 어느 메시지까지 읽었는지를 유지한다.
주어진 파티션의 각 메시지는 고유한 오프셋을 가지며, 파티션 별로 다음 번에 사용가능한 오프셋 값을 저장한다.
(카프카 자체에 오프셋 정보를 저장함)
Kafka 0.9 버전 이후부터는
컨슈머 그룹의 오프셋이 자동으로 Kafka 내부 토픽인 __consumer_offsets 에 저장됩니다.
이 방식은 컨슈머 그룹이 재시작되거나 장애가 발생해도
오프셋을 복구할 수 있도록 도와줍니다.
컨슈머는 읽기 작업을 정지했다가 재개했을 때 오프셋 정보로부터 마지막으로 읽은 메시지의 바로 다음 메시지부터 읽을 수 있다.
컨슈머는 컨슈머 그룹의 일원으로써 작동하며,
각 컨슈머 그룹은 하나 이상의 컨슈머로 이루어진다.
컨슈머 그룹은 각 파티션이 하나의 컨슈머에 의해서만 읽히도록 한다.
이 컨슈머 그룹으로 대량의 메시지를 갖는 토픽을 읽기 위해 컨슈머들을 수평 확장할 수 있다.
또한 컨슈머 중 한개가 장애가 발생해도,
그룹 안의 다른 컨슈머들이 장애가 발생한 컨슈머가 읽던 파티션을 재할당받은 뒤 이어서 데이터를 읽을 수 있다.
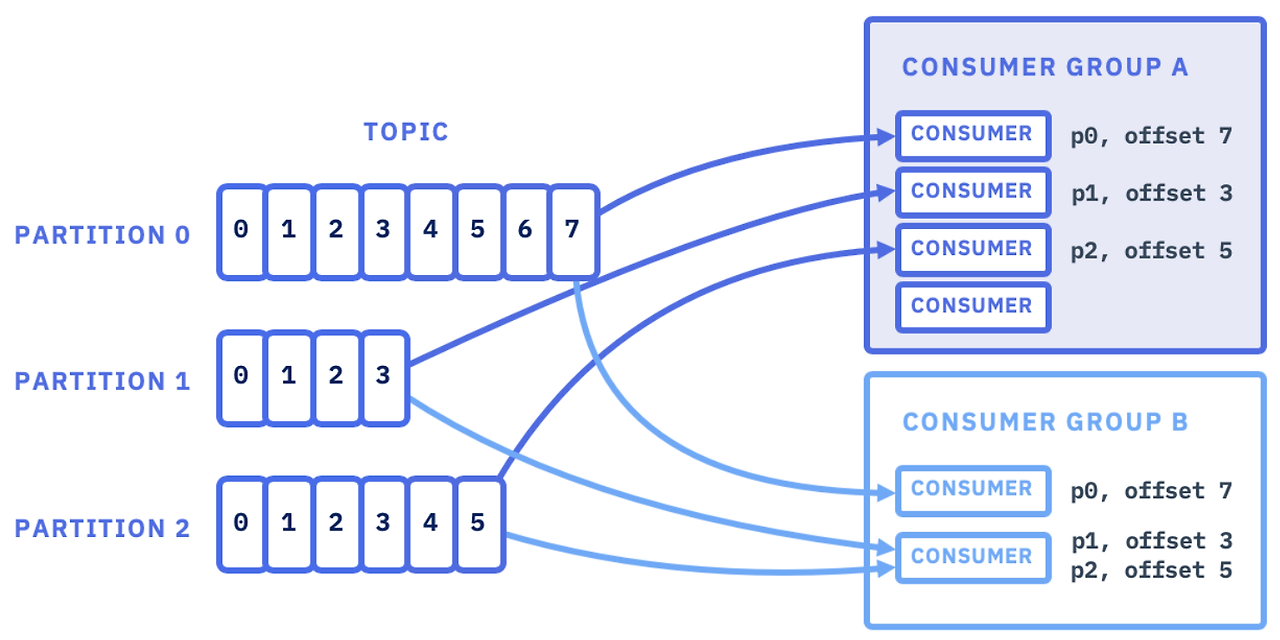
위 그림에서, 동일한 컨슈머 그룹 안에서의 각 컨슈머는 하나의 파티션만 읽고 있다.
즉, 컨슈머 그룹은 각 파티션이 하나의 컨슈머에 의해서만 읽히도록 한다.
단, 다른 컨슈머 그룹에서는 동일한 파티션을 읽을 수 있다.
위 그림에서 컨슈머 그룹 A의 컨슈머들은 각각 p0, p1, p2 파티션을 한개씩만 할당되어 읽을 수 있고,
하나의 컨슈머가 두개 이상의 파티션을 할당 받을 수 없다.
(컨슈머 그룹 B도 마찬가지)
단, P1은 컨슈머 그룹 A와 B가 모두 해당 토픽의 파티션을 모두 할당받을 수 있고,
컨슈머 그룹 별로 오프셋이 구분된다.
📌 1.2.5 브로커와 클러스터
하나의 카프카 서버를 브로커라고 하고,
브로커는 프로듀서로부터 메시지를 전달받아 오프셋을 할당한 뒤, 디스크 저장소에 쓴다.
브로커는 컨슈머의 파티션 읽기 요청도 처리하며 발행된 메시지를 컨슈머에 전달한다.
하나의 브로커는 하드웨어 성능에 따라 다르겠지만,
초당 수천 개의 파티션과 수백만 개의 메시지를 쉽게 처리할 수 있다.
카프카는 클러스터의 일부로써 작동하며, 하나의 클러스터 안에 여러 개의 브로커가 포함될 수 있다.
그중 하나의 브로커가 클러스터 컨트롤러 역할을 한다.
컨트롤러는 파티션을 브로커에 할당해주고, 장애가 발생한 브로커를 모니터링하는 등 관리 기능을 담당한다.

파티션은 클러스터 안의 브로커 중 하나가 담당하며, 그 브로커를 파티션 리더라 한다.
복제된 파티션이 여러 브로커에 할당될 수 있고, 이를 파티션의 팔로워라 한다.
모든 프로듀서는 리더 브로커에 메시지를 발행해야 하지만,
컨슈머는 리더와 팔로워 중 하나로부터 데이터를 읽을 수 있다.
📌 2.3 브로커 설정 핵심 매개변수
1) broker.id
모든 카프카 브로커는 정수값 식별자를 갖는다.
유지보수하다보면 브로커 ID에 해당하는 호스트 이름을 찾는 것도 부담스럽기 때문에
호스트 별로 고정된 값을 사용하는 것이 강력히 권장된다.
ex) host1.example.com 과 같이 호스트명에 고유 번호가 포함되어있다면, broker.id에 1을 할당한다.
2) zookeeper.connect
주키퍼의 메타데이터가 저장되는 주키퍼의 위치를 가리킨다.
...
...
🖇️ 2.3.2 토픽 별 기본값
1) num.partitions
새로운 토픽이 생성될 떄 몇 개의 파티션을 가질지 결정한다. (기본값은 1)
토픽의 파티션 개수는 늘릴 수만 있고 줄일 수는 없다.
파티션은 카프카 클러스터 안에서 토픽의 크기가 확장되는 방법이다.
따라서 브로커가 추가될 때 클러스터 전체에 걸쳐 메시지 부하가 고르게 분산되도록 파티션 개수를 잡아주는 게 중요하다.
많은 사용자들은 토픽 당 파티션 개수를 클러스터 내 브로커의 수와 맞추거나 배수로 설정한다.
이렇게 하면 브로커들 사이에 파티션을 고르게 분산시킬 수 있고,
결과적으로 메시지 부하 역시 고르게 분산된다.
위 파티션 그림 예시에서, 토픽 별 파티션의 갯수가 브로커의 갯수와 동일하게 구성되어있다. (3개)
만약 메시지가 더 많아 파티션을 추가해야 한다면, 3의 배수인 6, 9... 개로 파티션을 확장하여
각 브로커 별로 파티션을 고르게 분산시킬 수 있다.
📌 파티션 수는 어떻게 결정해야 할까?
파티션 수를 결정할 때 고려해야할 요소엔 여러가지가 있다.
- 토픽에 대해 달성하고자 하는 처리량은 대략 어느정도인가?
ex) 쓰기 속도가 초당 100KB / 1GB이여야 한다. - 단일 파티션에 대해 달성하고자 하는 최대 읽기 처리량은 어느정도인가?
하나의 파티션은 항상 하나의 컨슈머만 읽을 수 있음.
만약 컨슈머가 느리게 데이터를 DB에 쓰는데, DB의 쓰기 스레드 각각이 초당 50MB 이상을 처리할 수 없다면,
하나의 파티션에서 읽어올 수 있는 속도는 초당 50MB로 제한된다.
- 프로듀서가 컨슈머에 비해 훨씬 더 빠른 것이 보통이기 때문에 각 프로듀서가 단일 파티션에 쓸 수 있는 최대 속도에 대한 추정은 패스해도 됨
- 키 값을 기준으로 파티션을 결정하는 경우, 나중에 파티션을 추가하고자 하면 기존의 파티션 룰이 깨지고 전반적으로 리밸런싱이 일어아냐 하기 때문에 골치 아파진다. 따라서 현재 사용량이 아닌 미래의 사용량 예측값을 기준으로 처리량을 계산해야 함.
- 각 파티션은 브로커의 메모리와 다른 자원들을 사용하며, 메타데이터 업데이트나 리더 역할 변경에 걸리는 시간 역시 증가된다.
- 데이터를 미러링 구성할 경우 큰 파티션이 병목이 되는 경우가 많고, 파티션이 너무 많은 경우 병렬 처리 때문에 본의아니게 IOPS (디스크의 초당 입출력) 양이 증가할 수 있다.
따라서 파티션은 많으면 좋지만 그렇다고 너무 많아선 안된다.
토픽의 목표 처리량 / 컨슈머의 예상 처리량 => 파티션 갯수로 추정 가능
ex) 토픽에 초당 1GB(1024MB)를 읽거나 써야함 / 컨슈머 하나는 초당 50MB 처리가 가능하다 => 최소 20개의 파티션 필요
책에서는 매일 디스크 안에 저장되어있는 파티션 용량은 6GB미만으로 유지하는 것이
대체로 결과가 좋았다고 함.
파티션은 일단 작은 크기로 시작해서 나중에 필요할 때 확장하는 것이 처음부터 너무 크게 시작하는 것보다 쉽다.
https://www.confluent.io/blog/how-choose-number-topics-partitions-kafka-cluster/
How to Choose the Number of Topics/Partitions in a Kafka Cluster? | Confluent
Confluent is building the foundational platform for data in motion so any organization can innovate and win in a digital-first world.
www.confluent.io
3. 카프카 프로듀서 : 카프카에 메시지 쓰기
카프카를 큐로 사용하든, 메시지 버스나 데이터 저장 플랫폼으로 사용하든,
카프카를 사용할 때는 카프카에 데이터를 쓰는 프로듀서나 읽어올 때 쓰는 컨슈머,
혹은 두 가지 기능 모두를 수행하는 애플리케이션을 작성해야 한다.
그중 프로듀서를 애플리케이션으로 구현하는 방법, 각종 설정들, 아파치 에이브로를 사용하여 레코드에 스키마를 적용하는 방법,
인터셉터나 파티셔너를 애플리케이션에 구현하는 방법을 이번 장에서 소개한다.
📌 3.1 프로듀서 개요
애플리케이션이 카프카에 메시지를 써야 하는 경우?
- 감사, 분석을 목적으로 한 사용자 행동 기록
- 성능 매트릭 기록
- 로그 메시지 저장
- 도메인 이벤트 로그 저장
- 스마트 가전에서의 정보 수집
- 다른 애플리케이션의 비동기적 통신 수행
- 임의의 정보를 DB에 저장하기 전 버퍼링
이렇게 목적이 다양한 만큼 요구 사항 역시 다양한데, 아래와 같은 메시징 요구사항을 분석해야 한다.
- 모든 메시지가 중요해서 유실이 허용되지 않은지?
- 메시지 중복 발행이 허용되는지? 컨슈머 측에서 멱등성을 보장하도록 설계되어 있는지?
- 반드시 지켜야 할 지연이나 처리율이 있는지?
🖇️ 3.1.2 카프카에 데이터를 전송하는 과정
ProducerRecord 객체를 생성함으로써 카프카에 메시지를 쓰는 작업이 시작된다.
레코드에 저장될 토픽, 벨류는 필수값이며 키와 파티션 지정은 선택사항이다.
1) ProducerRecord 객체를 생성한다.
2) Serializer를 통해 레코드를 직렬화 한다.
즉, 키,값 정보를 담은 Record 객체가 네트워크 상에서 전송될 수 있도록 직렬화하여 바이트 배열로 변환한다.
3) Partitioner를 이용하여 어느 파티션으로 보낼지 결정한다.
일반적으로 ProducerRecord 객체의 키값을 사용하여 파티션을 결정한다.
이 단계에서 레코드가 전송될 토픽과 파티션이 결정된다.
4) 레코드를 같은 토픽과 파티션으로 전송될 레코드들을 모든 레코드 배치에 추가한다.
별도의 스레드가 이 배치를 적절한 카프카 브로커에게 전송한다.
5) 브로커에 메시지가 성공적으로 저장되면, 토픽, 파티션, 레코드의 오프셋을 담은 RecordMetadata 객체를 리턴한다.
만약 메시지 저장에 실패했을 경우 브로커는 에러를 리턴하고, 프로듀서는 에러를 수신하면
메시지 쓰기를 포기하고 사용자에게 에러를 리턴하기 전까지 몇 번 더 재전송을 시도한다.
📌 3.2 카프카 프로듀서 생성하기
Properties kafkaProps = new Properties();
kafkaProps.put("bootstrap.servers", bootstrapServers);
kafkaProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
bootstap.servers
- 프로듀서가 사용할 브로커의 host:port 목록이다.
여기에 모든 브로커 리스트를 포함할 필요는 없으나, 다른 브로커 중 하나가 작동을 정지하는 경우에도
프로듀서가 클러스터에 연결할 수 있도록 최소 2개 이상 지정할 것을 권장한다.
key.serializer
카프카에 쓸 레코드의 키 값을 직렬화 하기 위해 사용하는 시리얼라이저 클래스 이름
자주 사용되는 타입은 카프카의 client 패키지에 포함되어있으므로 시리얼라이저를 직접 구현할 필요가 없다.
(ByteArraySerializer, StringSerializer, IntegerSerializer ... )
키 값이 없어도 이 값을 설정해줘야 하며, VoidSerializer를 사용하여 키 값을 void 타입으로 설정할 수 있음.
value.serializer
카프카에 쓸 레코드의 밸류값을 직렬화하기 위해 사용하는 시리얼라이저 클래스 이름이다.
아래는 필수 속성만 지정하고, 나머지는 전부 기본 설정값을 사용하여 카프카 프로듀서를 생성하는 코드 예시이다.
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class SimpleKafkaProducer {
public static void main(String[] args) {
// Kafka Producer 설정
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092"); // 카프카 브로커 주소
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// KafkaProducer 생성
try (Producer<String, String> producer = new KafkaProducer<>(props)) {
String topic = "test-topic";
String key = "key1";
String value = "Hello, Kafka!";
// 메시지 전송
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record);
System.out.println("Message sent successfully");
} catch (Exception e) {
e.printStackTrace();
}
}
}
📌 카프카 메시지 전송 방법
1) Fire-and-Forget (파이어 앤 포겟)
- 메시지를 서버에 전송만 하고 브로커 저장에 성공 혹은 실패 여부에 신경 쓰지 않는다. (빠름)
카프카는 가용성이 높고, 프로듀서는 자동으로 전송 실패한 메시지를 재전송 시도하기 때문에
대부분의 경우에 메시지는 성공적으로 전달된다 - 재시도할 수 없는 에러가 발생하거나, 타임아웃이 발생했을 경우 메시지는 유실되며,
애플리케이션은 여기에 대해 아무런 정보나 예외를 전달받지 않게 된다. - 예시: producer.send(record);
2) Synchronous Send (동기 전송)
- send() 메서드 호출 후 get()을 사용하여 응답을 기다려 실제 성공 여부를 확인한다.
- 메시지 전송 성공 여부를 확인 가능하지만 성능이 저하될 수 있음.
- 예시: producer.send(record).get();
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class SyncKafkaProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
try (Producer<String, String> producer = new KafkaProducer<>(props)) {
String topic = "sync-topic";
String key = "key1";
String value = "Hello, Kafka (Sync)!";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// 동기 전송: send() 호출 후 get()을 사용하여 응답을 기다림
RecordMetadata metadata = producer.send(record).get();
System.out.printf("Message sent to partition %d with offset %d%n",
metadata.partition(), metadata.offset());
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
}
}
3) Asynchronous Send with Callback (비동기 전송 + 콜백)
- 메시지를 비동기적으로 전송하고, 전송 성공 또는 실패 여부를 콜백을 통해 확인하는 방식
- 성능과 안정성을 모두 고려한 방식.
- 이 방식은 동기 방식에 비해 성능이 뛰어나지만, 실패 시 적절한 오류 처리가 필요하다.
// 콜백 클래스 구현
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.KafkaException;
import org.apache.kafka.common.errors.InterruptException;
import org.apache.kafka.common.errors.RecordTooLargeException;
import org.apache.kafka.common.errors.SerializationException;
import org.apache.kafka.common.errors.TimeoutException;
import java.util.logging.Level;
import java.util.logging.Logger;
public class KafkaSendCallback implements Callback {
private static final Logger logger = Logger.getLogger(KafkaSendCallback.class.getName());
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
// 성공적으로 메시지가 전송된 경우
logger.info(String.format("Message sent successfully to topic=%s partition=%d offset=%d",
metadata.topic(), metadata.partition(), metadata.offset()));
} else {
// 예외 발생 시 처리
if (exception instanceof TimeoutException) {
logger.log(Level.WARNING, "Message send timed out. Consider increasing retries or adjusting timeout settings.", exception);
// 재시도 로직 추가 가능
} else if (exception instanceof SerializationException) {
logger.log(Level.SEVERE, "Serialization error while sending message. Check the data format and serializer configuration.", exception);
// 문제 데이터 검출 후 예외 처리
} else if (exception instanceof InterruptException) {
logger.log(Level.SEVERE, "Thread was interrupted during message send. Restoring interrupt state.", exception);
Thread.currentThread().interrupt(); // 인터럽트 상태 복원
} else if (exception instanceof RecordTooLargeException) {
logger.log(Level.SEVERE, "Message is too large. Consider splitting the message or increasing max request size.", exception);
// 메시지 크기 조정 또는 분할 전송 로직 추가 가능
} else if (exception instanceof KafkaException) {
logger.log(Level.SEVERE, "Kafka internal error occurred. Investigate broker health.", exception);
// 장애 감지 및 알림 로직 추가 가능
} else {
logger.log(Level.SEVERE, "An unknown error occurred while sending message.", exception);
// 기타 예외 처리
}
}
}
}
// 구현한 콜백 클래스를 이용하여 프로듀서 비동기 메시지 전송
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class AsyncProducerWithCustomCallback {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
try (Producer<String, String> producer = new KafkaProducer<>(props)) {
String topic = "async-topic";
String key = "key123";
String value = "Hello, Kafka with Custom Callback!";
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
// 비동기 전송 (커스텀 콜백 사용)
producer.send(record, new KafkaSendCallback());
System.out.println("Message sent asynchronously with custom callback.");
}
}
}
Callback 클래스를 직접 구현하려면 org.kafka.clientes.producer.Callback 인터페이스를 구현하고,
위 코드 예시처럼 onCompletion 메서드를 오버라이딩하면 된다.
만약 카프카가 에러를 리턴한다면 onCompletion 메서드가 null이 아닌 Exception 객체를 받게 된다.
따라서 콜백 메서드에서 발생 가능한 Exception들을 분석하여 적절한 예외처리를 작성해줘야 한다.
🔎 예상 가능한 예외들
Kafka 메시지 전송 과정에서 발생할 수 있는 주요 예외는 다음과 같다.
| TimeoutException | 메시지가 지정된 시간 내에 전송되지 못한 경우 발생 | 재시도 또는 로그 기록 후 경고 |
| SerializationException | 메시지 직렬화 중 오류 발생 (예: JSON 변환 오류) | 잘못된 데이터 검출 후 로깅 |
| InterruptException | 쓰레드가 인터럽트되어 전송이 중단된 경우 | 현재 쓰레드의 인터럽트 상태 유지 |
| KafkaException | 카프카 내부 오류 (브로커 문제 등) | 알림을 보내고 장애 감지 |
| RecordTooLargeException | 메시지 크기가 브로커 설정 제한보다 클 때 발생 | 메시지를 분할하여 재전송 |
4. 주요 예외 처리 전략
- TimeoutException 발생 시
- 로그에 경고 메시지를 남김
- retries 설정 증가 또는 linger.ms 조정 가능
- SerializationException 발생 시
- 데이터가 직렬화되지 않는 문제를 로깅 후 확인
- JSON 변환 오류인지, Kafka 설정 문제인지 확인 후 조치
- InterruptException 발생 시
- 현재 쓰레드의 인터럽트 상태를 복원하여 정상 종료
- RecordTooLargeException 발생 시
- max.request.size 및 message.max.bytes 조정 필요
- 메시지를 분할하여 전송하는 전략 고려
- KafkaException 발생 시
- 브로커 상태 점검
- 장애 알림 시스템 연동 가능
📌 3.4 프로듀서 설정하기
client.id
임의의 문자열을 사용하여 프로듀서를 구분하기 위한 식별자
브로커는 프로듀서가 보내온 메시지를 서로 구분하기 위해 이 값을 사용한다.
이 값을 잘 선택해야 문제가 발생했을 때 트러블슈팅을 쉽게 할 수 있다.
Kafka 브로커의 로그에서 특정 client.id의 활동을 추적할 수 있고,
lient.id별로 전송 속도, 실패율, 지연 시간 등을 측정할 수 있음.
Prometheus + Grafana를 사용할 경우, client.id별로 메트릭을 필터링하여 확인 가능.
(1) 로그 및 모니터링에서 프로듀서 구분
- 여러 개의 프로듀서가 있을 때, client.id를 명확히 설정하면 어떤 프로듀서가 문제를 발생시켰는지 식별 가능
(2) 성능 및 리소스 사용량 분석
- Kafka 브로커는 client.id별로 전송 속도, 오류율, 메시지 전송량 등을 기록
- 각 프로듀서의 성능을 모니터링할 때 필수적
(3) 오류 및 트러블슈팅 대응 용이
- 프로듀서가 메시지를 전송할 때 client.id를 기반으로 브로커 로그에 기록됨
- 장애 발생 시 해당 프로듀서만 재기동하거나 설정을 변경하는 등의 대응이 가능
ex) 서비스 별로 식별자 구성
client.id=order-service-producer
ex2) 서버 노드 별로 구성 (scale-out 환경)
client.id=payment-producer-node-1
ex3) 랜덤한 Unique ID 할당 (컨테이너 환경)
client.id=my-service-producer-{random_host_name}
acks (메시지 유실 가능성)
Kafka에서 acks(Acknowledgment) 설정은 메시지 유실 가능성과 성능에 중요한 영향을 미친다.
브로커가 프로듀서에게 메시지를 성공적으로 받았음을 어떤 조건에서 응답할지(acks 값) 에 따라 성능과 신뢰성이 결정된다.
| acks | 동작 방식 | 성능 | 메시지 유실 가능성 |
| acks=0 | 프로듀서는 브로커 응답 없이 바로 성공 처리 | 가장 빠름 | 높음 (손실 가능) |
| acks=1 | 리더 파티션이 메시지를 받으면 성공 응답 | 빠름 | 일부 손실 가능 |
| acks=all | 모든 ISR(복제된 노드)이 메시지를 받으면 성공 응답 | 느림 | 가장 안전 (손실 가능성 낮음) |
1) acks=0 (브로커 응답 없음)
🔹 동작 방식
- 프로듀서는 브로커가 메시지를 정상적으로 받았는지 확인하지 않고 즉시 전송 성공 처리
- 네트워크 또는 브로커 장애 발생 시, 메시지가 손실될 가능성이 높음
🔹 메시지 유실 가능성
✅ 장점:
- 가장 빠른 성능 (네트워크 대기 시간 없음)
- 초고속 메시지 전송이 필요한 상황에서 유용
⚠️ 단점:
- 브로커가 메시지를 받지 못해도 프로듀서는 성공으로 간주 → 데이터 손실 가능성 높음
- 전송 실패 시 재시도(retries)도 불가능
🔹 사용 예시
- 로그 수집 시스템 (일부 로그 손실이 허용되는 경우)
- 실시간 스트리밍 데이터 (ex. IoT 센서 데이터, 메트릭 수집)
- 메시지 손실이 허용되는 고성능 트랜잭션
✅ 👉 트러블슈팅 대응:
- acks=0을 사용할 경우 프로듀서에서 메시지를 별도로 저장 후 확인하는 로직 필요
2) acks=1 (리더 파티션만 확인)
🔹 동작 방식
- Kafka 브로커의 리더 파티션이 메시지를 받으면 프로듀서에게 성공 응답
- ISR(복제본 노드)에는 저장되었는지 확인하지 않음
🔹 메시지 유실 가능성
✅ 장점:
- acks=0보다 안전함 (리더가 받으면 최소한 한 번 저장됨)
- acks=all보다 성능이 빠름
⚠️ 단점:
- 리더가 메시지를 받은 후 복제되기 전에 장애 발생 시 메시지 유실 가능
- ISR(복제본)에 데이터가 저장되지 않아도 성공 응답을 보내므로 브로커 장애 시 데이터 유실 위험 존재
- 즉 리더에 크래시가 난 상태에서 해당 메시지가 복제가 안된 채로 새 리더가 선출될 경우 메시지 유실 가능
🔹 사용 예시
- 중간 정도의 신뢰성이 필요한 경우 (ex. 일반적인 이벤트 로그)
- 신뢰성과 성능의 균형이 필요한 서비스
- 단기적으로 일부 데이터 손실이 허용될 수 있는 환경
✅ 👉 트러블슈팅 대응:
- acks=1 사용 시 retries 값을 증가시키고, enable.idempotence=true를 설정하면 일부 신뢰성 개선 가능
3) acks=all (모든 ISR 복제본 확인)
🔹 동작 방식
- Kafka 브로커의 모든 ISR(복제된 노드)이 메시지를 받았을 때 프로듀서에게 성공 응답
- 리더뿐만 아니라 팔로워 복제본도 메시지를 저장해야 하므로 가장 신뢰성이 높음
- 카프카 3.0 버전 이후 부터는 enable.idempotence=true, acks=all 이 기본 옵션으로 설정되어있음.
🔹 메시지 유실 가능성
✅ 장점:
- 메시지가 ISR 복제본에도 저장되므로 브로커 장애가 발생해도 데이터 손실이 거의 없음
- 가장 신뢰성이 높은 설정 (데이터 유실 가능성이 가장 낮음)
⚠️ 단점:
- ISR(복제본 노드)이 동기화될 때까지 기다려야 하므로 성능이 느려질 수 있음
- 높은 가용성을 위해 충분한 수의 복제본 설정(min.insync.replicas)이 필요
🔹 사용 예시
- 금융 트랜잭션 (결제 시스템, 은행 서비스)
- 고객 데이터 저장 (주문 데이터, 사용자 계정 생성)
- 데이터 손실이 절대 허용되지 않는 경우
✅ 👉 트러블슈팅 대응:
- min.insync.replicas 설정을 2 이상으로 조정하여, 충분한 복제본이 유지되지 않으면 메시지 전송을 실패하도록 설정
- acks=all을 사용할 경우 retries와 enable.idempotence=true도 설정하여 신뢰성 강화
📌 3.4.3 메시지 전달 시간에 관한 설정
프로듀서 측면에서 send() 메서드를 호출했을 때 성공 혹은 실패하기까지 얼마나 시간이 걸리는가?
이 시간은 카프카가 성공적으로 응답을 내려보낼때까지 클라이언트가 기다릴 수 있는 시간이며,
요청 실패를 인지하고 포기할 때까지 기다리는 시간이기도 하다.
카프카 2.1부터 개발진은 ProducerRecord 객체를 보낼때 걸리는 시간을 2구간으로 나누어서 설명함.

1) send()에 대한 비동기 호출 후 결과를 리턴할 때까지 걸리는 시간
2) send()에 대한 비동기 호출이 성공적으로 리턴한 시간부터 (성공 or 실패) 콜백이 호출될 때까지 걸리는 시간
위 그림을 보며 각 설정에 대한 설명을 살펴보자.
max.block.ms
send()를 호출했을 때 partitionsFor를 호출해서 명시적으로 메타데이터를 요청했을 때.
프로듀서의 전송 버퍼가 가득 차거나 메타데이터가 아직 사용 가능하지 않을 때 블록된다.
이 상태에서 max.block.ms만큼 시간이 흐르면 예외가 발생한다.
linger.ms (배치를 위한 메시지 지연 시간)
KafkaProducer는 현재 배치가 가득 차거나 linger.ms에 설정된 제한 시간이 되었을 때 메시지 배치를 전송한다.
기본적으로 프로듀서는 메시지 전송에 사용할수 있는 스레드가 있을 때 곧바로 전송한다.
이 값을 0보다 큰 값으로 설정하면, 프로듀서가 배치 전송 전에 메시지를 추가할 수 있도록 몇 ms 더 기다릴 수 있다.
대신 지연시간은 좀 생기지만 처리율을 크게 증대시킬 수 있다.
- 높은 처리량이 필요한 경우 (batch.size와 함께 조정)
- 소량의 메시지를 너무 자주 전송하는 경우 최적화 가능
delivery.timeout.ms (메시지 전송 최대 대기 시간)
send()가 문제없이 리턴되고 레코드가 배치에 저장된 시점부터,
브로커의 응답을 받거나 전송을 포기하게 되는 시점까지의 제한시간을 결정한다. (재시도를 포함한 전체 시간)
이 값은 linger.ms, request.timeout.ms보다 커야하고 조건을 벗어난 설정으로 카프카 프로듀서를 생성하면 예외가 발생한다.
위 이미지와 같이 linger.ms, request.timeout.ms, Retry.backoff.ms를 모두 합친 값보다 크거나 같다.
만약 프로듀서가 재시도하는 도중 이 값의 시간이 초과하면, 브로커가 리턴한 에러에 해당하는 예외와 함께 콜백이 호출된다.
또는 레코드 배치가 전송을 기다리는 도중 이 값의 시간이 초과하면 타임아웃 예외와 함께 콜백이 호출된다.
- 네트워크가 불안정한 환경에서 재시도를 길게 허용할 경우 설정
- retries 값이 높을 때, 무한 재시도를 방지하기 위해 적절한 delivery.timeout.ms 설정 필요
request.timeout.ms (브로커 응답 대기 시간)
프로듀서가 데이터 전송시 카프카 서버로부터 응답을 받기 위해 얼마나 기다릴 것인지 결정한다.
각각의 쓰기 요청 후 전송을 포기하기까지 대기하는 시간
위 이미지처럼 재시도 시간이나 실제 전송 이전에 소요되는 시간을 포함하지 않는다.
카프카 서버의 응답 없이 타임아웃 발생시 프로듀서는 재전송을 시도하거나 TimeoutException과 함께 콜백을 호출한다.
- ISR 복제본이 많고 acks=all을 사용할 때 너무 짧게 설정하면 불필요한 타임아웃이 발생할 수 있음
- 네트워크 지연이 발생할 수 있는 환경에서는 값을 증가시키는 것이 좋음
retries, retry.backoff.ms (실패한 메시지 재시도)
retries는 프로듀서가 카프카 서버로부터 에러 메시지를 받았을 때,
메시지를 재전송하는 횟수를 결정한다.
retry.backoff.ms는 재시도 간격을 조정하며 기본값은 100ms이다.
- 네트워크가 불안정한 환경에서 재시도를 통해 메시지 손실 방지
- acks=all을 사용할 때 일시적인 ISR 복제본 문제 해결 가능
| 설정값 | 설명 | 기본값 |
| linger.ms | 배치 전송을 위해 메시지를 지연시키는 시간 | 0ms |
| delivery.timeout.ms | 메시지 전송을 위한 최대 대기 시간 (retries 포함) | 120000ms (2분) |
| request.timeout.ms | 브로커가 응답하지 않을 경우 타임아웃 대기 시간 | 30000ms (30초) |
| retries | 메시지 전송 실패 시 재시도 횟수 | 2147483647 (무한) |
| retry.backoff.ms | 실패 후 재시도 간격 | 100ms |
📌 그 외 눈여겨 볼 설정들 👀
batch.size
- batch.size는 한 개 배치가 가질 수 있는 최대 크기(바이트 단위)를 지정
- 프로듀서는 동일한 파티션으로 보내는 메시지들을 하나의 배치로 묶어 전송
- 배치 크기가 커지면 네트워크 오버헤드를 줄여서 처리량 증가 가능
- 하지만, 너무 크면 메시지 지연(latency)이 증가할 수도 있음
- 배치가 batch.size에 도달하거나 linger.ms 시간이 지나면 전송됨
- linger.ms=0이면 도착한 메시지가 즉시 전송되므로 batch.size를 크게 설정해도 효과가 적음
- 높은 처리량(throughput)이 필요한 경우 → batch.size를 크게 설정
- 실시간성이 중요한 서비스 → batch.size를 작게 설정
max.in.flight.requests.per.connection
- 하나의 Kafka 브로커 연결에서 동시에 보낼 수 있는 최대 요청 개수
- 기본값은 5, 즉 최대 5개의 요청을 병렬로 보낼 수 있음
- 성능을 높이지만, 너무 크게 설정하면 순서가 바뀌는 문제(Out-of-Order) 발생 가능
- max.in.flight.requests.per.connection=1이면 요청이 하나 처리될 때까지 다음 요청을 보내지 않음 (FIFO 보장)
- max.in.flight.requests.per.connection>1이면 여러 개의 요청을 동시에 처리 가능 (성능 향상, 하지만 순서 뒤바뀔 가능성 있음)
- enable.idempotence=true 설정 시 자동으로 max.in.flight.requests.per.connection=5 이하로 제한됨
🔹 max.in.flight.requests.per.connection 값에 따른 동작 비교
설정값순서 보장성능재시도 시 문제 발생 가능성
| 설정값 | 순서 보장 여부 | 속도 | 재시도시 문제 가능성 |
| 1 | ✅ 순서 완벽 보장 | ❌ 느림 | 🚫 없음 |
| >1 (예: 5) | ❌ 순서가 깨질 수 있음 | ✅ 빠름 | 🔥 Out-of-Order 가능 |
| 5 + enable.idempotence=true | ✅ 보장됨 (Kafka 3.0 이상) | ✅ 적절한 성능 | 🚫 없음 |
enable.idempotence (멱등성 전송)
- 중복 메시지 전송 방지
- Kafka 프로듀서가 중복 메시지를 보내더라도 브로커에서 하나만 저장하도록 보장
- Exactly-Once 전송 보장(중복 없이 한 번만 메시지 전송됨)
- 결제 시스템, 주문 처리 등 중복 메시지가 치명적인 서비스에서 사용
- 로그 시스템 등 정확한 데이터가 필요한 경우
✅ 동작 방식:
- 프로듀서가 PID(Producer ID)를 생성하고, Sequence Number를 메시지에 추가
- 브로커는 같은 PID의 중복된 Sequence Number 메시지를 무시하여 중복 방지
- enable.idempotence=true 설정 시 자동으로 아래 값이 설정됨
retries=Integer.MAX_VALUE # 무한 재시도
max.in.flight.requests.per.connection=5 # 순서 뒤바뀜 방지
acks=all # 모든 리플리카가 확인해야 성공 처리
🔹 3. 최적의 조합 설정 예시
✔️ (1) 실시간성이 중요한 애플리케이션
linger.ms=0
delivery.timeout.ms=5000
request.timeout.ms=2000
retries=2
retry.backoff.ms=200
✅ 사용 사례:
- 채팅 서비스, 실시간 알림, 금융 트랜잭션
- 메시지를 최대한 빠르게 전송해야 하므로 배치 전송(liger.ms) 비활성화
- 전송 실패 시 재시도를 2번만 수행하여 빠르게 실패 처리
✔️ (2) 대량의 데이터를 처리하는 배치 시스템
linger.ms=50
delivery.timeout.ms=60000
request.timeout.ms=30000
retries=10
retry.backoff.ms=1000
✅ 사용 사례:
- 로그 수집, ETL 파이프라인, IoT 데이터 전송
- 성능을 위해 배치 전송(linger.ms=50) 활성화
- 메시지 유실을 방지하기 위해 충분한 재시도(retries=10) 설정
✔️ (3) 신뢰성이 중요한 금융 트랜잭션 시스템
acks=all
enable.idempotence=true
min.insync.replicas=2
linger.ms=5
delivery.timeout.ms=120000
request.timeout.ms=60000
retries=2147483647
retry.backoff.ms=500✅ 사용 사례:
- 결제 시스템, 주문 처리, 은행 거래
- 완벽한 신뢰성을 보장하기 위해 acks=all과 enable.idempotence=true 사용
- retries=2147483647로 설정하여 네트워크 장애가 있어도 영구적으로 메시지 보장
📌 3.6 파티션
메시지의 키는 하나의 토픽에 속한 여러 파티션 중 메시지가 저장될 파티션을 결정짓는 기준점이다.
만약 키가 null인 레코드가 주어질 경우, 레코드는 현재 사용 가능한 토픽의 파티션 중 하나에 랜덤하게 (라운드 로빈) 지정된다.
아래 예시는, 키가 특정 prefix string을 포함하는 경우 고정 파티션에 할당하는 예시를 보여준다.
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
public class CustomProductPartitioner implements Partitioner {
private static final String SPECIAL_PRODUCT_PREFIX = "SPECIAL_PRODUCT"; // 특정 상품 ID
private static final int FIXED_PARTITION = 0; // 특정 상품을 보낼 고정 파티션
private final AtomicInteger counter = new AtomicInteger(0); // 라운드 로빈 카운터
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
int numPartitions = cluster.partitionCountForTopic(topic); // 현재 토픽의 전체 파티션 개수
if (key instanceof String) {
String keyStr = (String) key;
if (keyStr.startsWith(SPECIAL_PRODUCT_PREFIX)) {
return FIXED_PARTITION; // 특정 상품 ID는 고정된 파티션으로
}
}
// 라운드 로빈 방식으로 파티션을 순차적으로 선택 (특정 상품이 아닌 경우)
return (counter.getAndIncrement() & Integer.MAX_VALUE) % numPartitions;
}
@Override
public void close() {
// 필요한 정리 작업 수행 (없다면 비워둠)
}
@Override
public void configure(Map<String, ?> configs) {
// 필요하면 설정값을 가져와서 초기화 가능
}
}
아래와 같은 케이스에서 키 별로 동일한 파티션에 할당되어야 하는 요구사항이 있을 수 있다.
| 주문, 금융 거래 | 순서 보장 필수 (ORDER_1234) |
| 세션 기반 서비스 | 같은 유저 이벤트 유지 (USER_1001) |
| IoT 센서 데이터 | 디바이스별 데이터 정합성 (SENSOR_ABC) |
| VIP 고객 관리 | 특정 고객 데이터 집중 관리 (VIP_500) |
| 데이터 로컬리티 최적화 | 서버, 창고, 데이터 센터 별 관리 (WAREHOUSE_007) |
| 국가/지역별 데이터 분배 | 지리적 특성을 고려한 저장 (COUNTRY_US) |
📌 Kafka 프로듀서의 접착성 처리 (Sticky Partitioning)란?
카프카 2.4 프로듀서부터 기본 파티셔너는 키 값이 null인 경우, 접착성 처리를 하기 위해 라운드 로빈 알고리즘을 사용한다.
Kafka 프로듀서에서 메시지를 특정 파티션에 "묶어서" 보내는 방식으로 배치(batch) 성능을 극대화하는 전략
이를 통해 네트워크 효율성 및 전송 성능을 높이는 역할.
기본적으로 Kafka 프로듀서는 Key 기반 파티셔닝 또는 라운드 로빈 방식으로 메시지를 분배한다.
✅ 너무 자주 파티션이 바뀌면 배치 전송 효과가 떨어질 수 있음
✅ 동일 파티션에 메시지를 모아서 보내면 성능이 향상됨
💡 Sticky Partitioner는 일정 기간 동안 특정 파티션을 유지하며 여러 개의 메시지를 모아 배치 전송하는 방식

🔹 Sticky Partitioning의 동작 방식
- 처음에는 특정 파티션을 무작위 선택
- 한동안 해당 파티션에 메시지를 계속 추가 (메시지 접착)
- 배치 크기(batch.size)가 가득 차거나 linger.ms 타임아웃이 되면 전송
- 그 후 새로운 파티션을 선택하여 같은 방식으로 메시지 전송
https://www.confluent.io/blog/apache-kafka-producer-improvements-sticky-partitioner/
Apache Kafka Producer Improvements: Sticky Partitioner
Apache Kafka 2.4 introduces sticky partitioning, allowing Kafka producers to assign keyless messages to partitions for data processing at lower latency.
www.confluent.io
'프로그래밍 > kafka' 카테고리의 다른 글
| [카프카 핵심 가이드] 4장 : 카프카 컨슈머 - 카프카에서 데이터 읽기 (0) | 2025.03.30 |
|---|





댓글 영역