고정 헤더 영역
상세 컨텐츠
본문
1) 트랜잭션의 개념
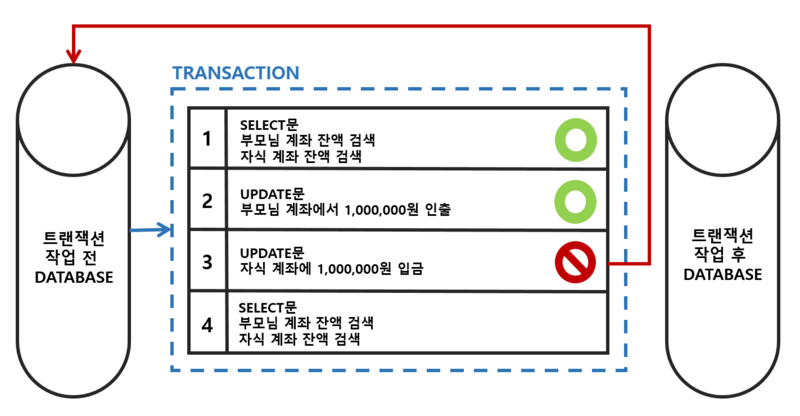
트랜잭션이란 "쪼갤 수 없는 업무 처리의 최소 단위"를 말한다.
흔히 드는 예시로는 은행의 ATM 거래를 자주 들어봤을 것이다.
은행 ATM이나 데이터베이스 등의 시스템에서 사용되는 더 이상 쪼갤 수 없는 업무 처리의 최소 단위이다.
예를 들어, A라는 사람이 B라는 사람에게 1,000원을 지급하고 B가 그 돈을 받은 경우,
이 거래 기록은 더 이상 작게 쪼갤 수가 없는 하나의 트랜잭션을 구성한다.
만약 A는 돈을 지불했으나 B는 돈을 받지 못했다면 그 거래는 성립되지 않는다.
이처럼 A가 돈을 지불하는 행위와 B가 돈을 받는 행위는 별개로 분리될 수 없으며
하나의 거래내역으로 처리되어야 하는 단일 거래이다.
이런 거래의 최소 단위를 트랜잭션이라고 한다.
트랜잭션 처리가 정상적으로 완료된 경우 커밋(commit)을 하고,
오류가 발생할 경우 원래 상태대로 롤백(rollback)을 한다.
데이터베이스 서버에 여러 개의 클라이언트가 동시에 액세스 하거나,
응용프로그램이 갱신을 처리하는 과정에서 중단될 수 있는 경우 등
데이터 부정합을 방지하고자 할 때 사용한다.
데이터베이스 기능 중, 트랜잭션을 조작하는 기능은 데이터베이스 완전성(integrity) 유지를 확신하게 한다.
http://wiki.hash.kr/index.php/%ED%8A%B8%EB%9E%9C%EC%9E%AD%EC%85%98
트랜잭션 - 해시넷
트랜잭션(transaction)이란 "쪼갤 수 없는 업무 처리의 최소 단위"를 말한다. 거래내역이라고도 한다. '트렌젝션'이 아니라 '트랜잭션'이 올바른 표기법이다. 영어로 간략히 Tx라고 표기하기도 한다.
wiki.hash.kr
2) 트랜잭션의 특징 (ACID)
이러한 데이터베이스의 트랜잭션이 안전하게 동작하기 위해서는 다음의 4가지 (ACID) 조건을 만족해야 한다.
각각에 대한 설명을 이해해보자.
원자성 (Atomicity)
트랜잭션이 데이터베이스에 모두 반영되던지, 아니면 전혀 반영되지 않아야 하며
작업이 부분적으로 실행되거나 중단되지 않는 것을 보장하는 것으로
All or Nothing의 개념으로서 작업 단위를 일부분만 실행하지 않는다는 것을 의미한다.
트랜잭션 실행 도중 문제가 발생했을 경우 중단된 상태가 아닌 모두 실패하거나,
모두 완성되거나 둘 중 하나의 상태가 되어야 한다.
트랜잭션이 원자성이라는 성질을 지니게 된 이유는
중간에 끊기게 되면 이후 해당 트랜잭션의 어디서부터 이어서 수행되어야 하는지 모르기 때문이다
트랜잭션에서 원자성은 수행하고 있는 트랜잭션에 의해 변경된 내역을 유지하면서,
이전에 커밋된 상태를 임시 영역에 따로 저장함으로써 보장한다.
즉, 현재 수행하고 있는 트랜잭션에서 오류가 발생하면 현재 내역을 날려버리고 임시 영역에 저장했던 상태로 롤백 한다.
이전 데이터들이 임시로 저장되는 영역을 롤백 세그먼트(rollback segment)라고 하며,
현재 수행하고 있는 트랜잭션에 의해 새롭게 변경되는 내역을 데이터베이스 테이블이라고 한다.
트랜잭션의 원자성은 롤백 세그먼트에 의해 보장된다고 할 수 있다.
일관성 (Consistency)
트랜잭션이 완료된 결괏값이 일관적인 DB 상태를 유지하는 것을 말한다.
시스템이 가지고 있는 고정요소는 수행 전과 후의 상태가 같아야 하며
트랜잭션이 진행되는 동안 데이터베이스가 변경되더라도,
업데이트된 데이터베이스로 트랜잭션이 진행되는 것이 아니라,
처음 트랜잭션을 진행하기 위해 참조한 데이터베이스로 진행된다.
이렇게 함으로써 각 사용자가 일관성 있는 데이터를 볼 수 있는 것이다.
트랜잭션 수행 전후의 데이터베이스 상태는 각각 일관성이 보장되는 서로 다른 상태가 된다.
예를 들어 Movie와 Video 테이블이 있을 때 Video 테이블의 기본 키(primary key)인 movie_id가 외래키로 존재한다고 가정한다.
만약 movie_id의 제약 조건이 Movie 테이블에서 변경되면,
Video 테이블에서도 movie_id가 변경되어야 한다.
한 쪽의 테이블에서만 데이터 변경사항이 이루어져서는 안되는 것이다.
이때 트랜잭션의 일관성을 보장하기 위한 방법은 어떤 이벤트와 조건이 발생했을 때, 트리거(Trigger)를 통해 보장하는 것이다.
트랜잭션 수행이 보존해야 할 일관성은 위 예시와 같이 기본 키, 외래 키 제약과 같은 명시적인 무결성 제약 조건들뿐만 아니라,
A에서 B로 돈을 이체할 때 A와 B 계좌의 돈의 총합이 같아야 한다는 사항과 같은 비명시적인 일관성 조건들도 있다.
격리성 (Isolation)
데이터베이스는 클라이언트들이 같은 데이터를 공유하는 것이 목적이므로 여러 트랜잭션이 동시에 수행되어야 한다.
이때 트랜잭션은 상호 간의 존재를 모르고 독립적으로 수행되어야 한다.
이를 유지하기 위해서는 여러 트랜잭션이 동시에 접근하는 데이터에 대한 제어가 필요하다.
여러 트랜잭션이 동시에 수행되더라도,
각각의 트랜잭션은 다른 트랜잭션의 수행에 영향을 받지 않고 독립적으로 수행되어야 한다.
한 트랜잭션에서 데이터베이스를 변경한 내용은 트랜잭션이 커밋되기 전까지는
다른 어떤 질의나 트랜잭션과도 고립되어야만 한다.
즉, 각 트랜잭션은 시스템 내에서 동시에 수행되고 있는 다른 트랜잭션들을 알지 못하는 것이다.
이러한 격리성을 지키기 위해 데이터베이스에서는 5단계의 트랜잭션 격리 레벨을 제공한다.
(아래에 각 격리 레벨에 대한 설명도 추가해놓음)
데이터를 거나 쓸 때는 문을 잠궈서 다른 트랜잭션이 접근하지 못하도록 고립성을 보장하고,
수행을 마치면 언락(unlock)을 통해 데이터를 다른 트랜잭션이 접근할 수 있도록 허용하는 방식을 통해 고립성을 보장할 수 있다.
트랜잭션에서는 데이터를 읽을 때, 여러 트랜잭션이 읽을 수는 있도록 허용하는 공유록(shared_lock)을 한다.
즉, 공유 록은 데이터 쓰기를 허용하지 않고 오직 읽기만 허용하는 것이다.
또한 데이터를 쓸 때는 다른 트랜잭션이 읽을 수도 쓸 수도 없도록 하는 배타 록(exclusive_lock)을 사용한다.
그리고 읽기, 쓰기 작업이 끝나면 언락을 통해 다른 트랜잭션이 록(lock)을 할 수 있도록 데이터에 대한 잠금을 풀어준다.
단, 록(lock)과 언락을 잘못 사용하면 모든 트랜잭션이 아무것도 수행할 수 없는 데드락(deadlock)상태에 빠질 수 있다.
지속성 (Durability)
트랜잭션이 정상적으로 종료된 다음에는 영구적으로 데이터베이스에 작업의 결과가 저장되어야 한다.
지속성(durability)은 트랜잭션의 성공 결과 값은 장애 발생 후에도 변함없이 보관되어야 한다는 것으로
트랜잭션이 정상적으로 완료된 경우에는 버퍼의 내용을 하드디스크(데이터베이스)에 확실히 기록해야 하며,
부분 완료(Partial Commit)된 경우에는 작업을 취소(Aborted)하여야 한다.
즉, 정상적으로 완료 혹은 부분 완료된 데이터는 DBMS가 책임지고 데이터베이스에 기록하는 성질이 지속성이며
영속성이라고 표현하기도 한다.
3) 트랜잭션의 격리 수준
앞에서 트랜잭션의 보장 조건 중 "격리성 (Isolation)"에 대한 설명이 있었다.
동시에 다수의 트랜잭션이 DB의 동일한 레코드에 접근하여 데이터를 읽거나 조작할 수 있는 상황은
충분히 존재할 수 있다.
아래와 같은 상황을 가정해보자.
만약에 A 트랜잭션이 상품 C의 가격을 1000원에서 2000원으로 업데이트를 하였고,
아직 커밋하지 않은 상태였다.
이때 동시에 B 트랜잭션이 동일한 상품 C 데이터를 읽으려고 할때
B 트랜잭션이 1000원을 읽게 해야 할까, 2000원을 읽게 해야 할까?
이렇게 동시 접근하는 데이터를 어느 정도까지 다른 트랜잭션에 격리시킬지의 단계를 설정할 수 있다.
즉, 다른 트랜잭션에서 일관성이 없는 데이터를 허용하도록 하는 수준을 결정할 수 있다.
격리 수준이 낮을 수록, 다른 트랜잭션들이 대기하는 성능은 빠르지만
다른 트랜잭션에서는 격리 수준이 낮으니 일관성 없는 데이터를 읽을 가능성이 높아지고,
격리 수준이 높을수록, 다른 트랜잭션에서 일관성 있는 데이터를 읽어서 처리하게 되지만,
그만큼 동시에 참여하는 트랜잭션들의 대기시간이 길어지게 된다.
따라서 성능과 격리 수준을 각 서비스에 따라 적절하게 고려하여 격리 레벨을 설정해야 한다.
3-1) 다수의 트랜잭션이 경쟁하는 상황에서 발생할 수 있는 데이터 불일치 문제
1) Dirty Read
선발주자 트랜잭션이 데이터를 업데이트 후, 아직 커밋하지 않은 상황에서
다른 트랜잭션에게 아직 커밋하지 않은 데이터에 대한 접근을 허용할 경우 발생할 수 있는 데이터 불일치이다.
트랜잭션의 격리 레벨 중 READ_UNCOMMITED에서 발생하는 문제이며, READ_COMMITTED에서 문제점이 해결된다.

위 이미지의 상황은 아래와 같다.
1. Alice 트랜잭션이 post 테이블의 id가 1인 데이터를 업데이트 후 아직 커밋하지 않은 상황이다.
2. Bob 트랜잭션이 Alice 트랜잭션이 아직 커밋하지 않은 데이터를 읽어서 title이 'ACID'로 업데이트 의 값을 읽어온다.
3. 예상치 못한 오류로 Alice 트랜잭션의 Update 작업이 롤백되어 데이터는 다시 title이 'Transaction'값으로 복원되었다.
4. 롤백 후 Bob 트랜잭션이 데이터를 다시 읽으면 title이 'Transaction'을 바뀌어있다.
동일한 데이터의 값이 2번에서와 다른 불일치 문제가 발생!
2) Non-Repeatable-Read
한 트랜잭션에서 읽은 데이터를 다른 트랜잭션에서 수정 및 삭제가 가능할 때 생기는 데이터 불일치 문제이다.
즉, 한 트랜잭션에서 읽은 데이터를 다른 트랜잭션에서 수정 및 삭제가 가능하다.

위 이미지의 상황은 아래와 같다.
1. Alice의 트랜잭션이 시작되고, post 테이블의 id가 1번인 레코드에 접근하려고 한다.
2. Bob의 트랜잭션도 시작되고, post 테이블의 id가 1번인 동일한 레코드를 읽는다.
3. Alice의 트랜잭션에서 해당 레코드의 title 데이터를 'ACID'로 업데이트 후 커밋한다.
4. Bob의 트랜잭션이 해당 데이터를 다시 읽었을 땐, Alice 트랜잭션이 해당 데이터를 수정했기 때문에,
2번에서 읽은 데이터가 다른 불일치가 발생한다!
Dirty Read에 비해서는 발생 확률이 적으며,
트랜잭션의 격리 레벨 중 READ_UNCOMMITED, READ_COMMITTED에서 발생하며,
REPEATABLE_READ에서 해결된다.
3) Phantom-Read
한 트랜잭션에서 일정 범위의 레코드를 두 번 이상 읽을 때 발생할 수 있는 데이터 불일치 상황이다.
하나의 트랜잭션에서 같은 쿼리를 두 번 실행했을 경우,
첫 번째 쿼리에서는 없던 유령(Phantom) 레코드가 추가되어 있거나, 삭제 되어 있을 수 있다.
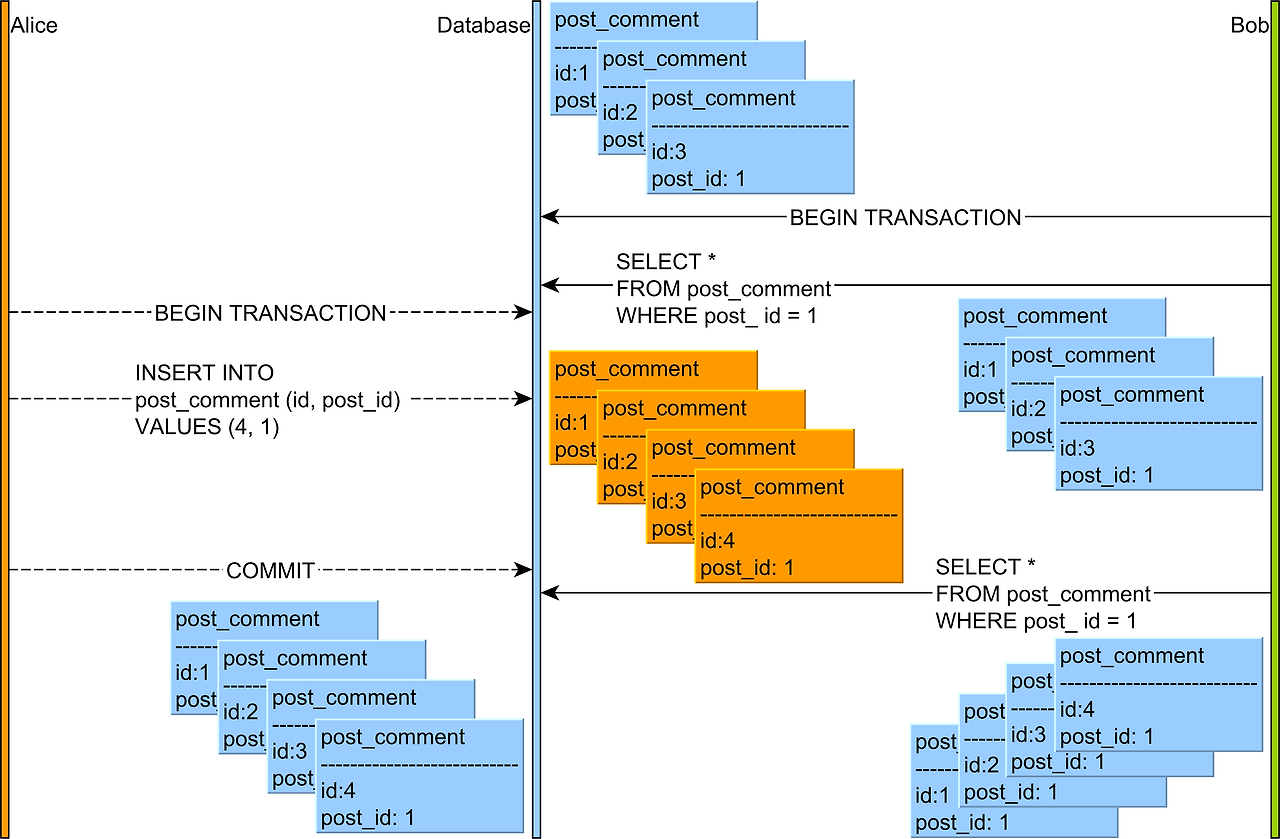
위 이미지의 상황은 아래와 같다.
1. Bob 트랜잭션은 post_comment 테이블에서 post_id가 1인 N개의 레코드를 읽고 있었다.
2. Alice 트랜잭션은 post_id가 1인 새로운 데이터를 Write 한 후 커밋하였다.
3. Bob 트랜잭션이 1번에서처럼 동일하게 post 테이블에서 post_id가 1인 레코드를 읽으면 2번에서 새로 추가된 레코드가 추가로 조회되는 데이터 불일치가 발생할 수 있다!
Phantom Read는 READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ 격리 레벨에서 발생 가능하며,
SERIALIZABLE 격리 레벨에서 해결된다.
이제 동일한 데이터에 다수의 트랜잭션이 경쟁하는 상황을 보았고,
각각의 트랜잭션 격리 레벨에서 이러한 경쟁상황들이 어떻게 해결되는지 살펴보자 :)
3-2) 트랜잭션 격리 수준의 종류
- DEFAULT

- 데이터베이스의 기본 설정 격리 수준을 따른다.
위 이미지처럼 org.springframework.transaction.annotation 패키지에 있는
@Transactional 어노테이션의 isolation 기본 설정값은 DEFAULT로 설정되어있다.
0) READ_UNCOMMITTED
가장 낮은 수준의 트랜잭션 격리 레벨이다.
이름처럼 다른 트랜잭션에서는 "아직 커밋되지 않은 데이터"를 읽을 수 있으므로
트랜잭션 기능을 거의 수행하지 않는다.
위에서 설명한 "트랜잭션 경쟁 상황에서 발생하는 데이터 불일치 케이스" 중
Dirty Read (+ Non-Repeatable-Read, Phantom-Read) 현상이 발생한다.
1) READ_COMMITTED (Oracle, H2 등 MySQL을 제외한 대부분의 DB에 설정된 기본 격리 수준)
다른 트랜잭션이 커밋하지 않은 데이터는 읽을 수 없다.
하지만 특정 데이터를 읽은 상태에서 다른 트랜잭션이 해당 데이터를 수정후 커밋할 수 있다.
READ_UNCOMMITTED에서 발생한 DIRTY_READ는 해결되었지만,
여전히 Non-Repeatable-Read, PHANTOM_READ가 발생할 수 있는 격리 레벨이다.
2) REPEATABLE_READ (MySQL에 설정된 기본 격리 수준)
트랜잭션 내에서 일단 한번 데이터를 읽어오면,
데이터를 읽어올 때마다 동일한 데이터를 읽어온다.
한 트랜잭션에서 읽은 데이터를 다른 트랜잭션이 수정할 수는 없지만, 새로운 데이터를 삽입할 수 있다.
새롭게 삽입된 데이터는 다른 트랜잭션에서도 읽을 수 있으므로,
PHANTOM READ가 발생할 수 있다.
3) SERIALIZABLE
모든 트랜잭션은 하나씩 차례대로 실행되는 것처럼 처리된다.
PHANTOM READ가 발생하지 않는다.
동시 처리 능력이 다른 격리 레벨보다 떨어지고 성능 저하가 발생할 수 있어 데이터베이스에서 거의 사용되지 않는다.
이렇게 격리 레벨 별로 발생할 수 있는 데이터 정합성 문제를 정리하면 아래와 같다.

4) 트랜잭션의 전파 옵션
1) REQUIRED (기본 옵션)

이미 존재하는 트랜잭션을 지원하며, 트랜잭션이 없다면 새 트랜잭션이 시작된다.
예외가 발생하면 롤백이 되고 호출한 곳에도 롤백이 전파된다.
만약, 해당 메서드가 호출한 곳와 별도의 쓰레드라면 어떤 동작이 일어날까?
답은 전파 레벨과 상관 없이 무조건 별도의 트랜잭션을 생성하여 해당 메서드를 실행한다.
- Spring은 내부적으로 트랜잭션 정보를 ThreadLocal 변수에 저장하기 때문에 다른 쓰레드로 트랜잭션이 전파되지 않는다.
2) SUPPORTS :
이미 존재하는 트랜잭션을 지원하고, 트랜잭션이 없으면 비트랜잭션으로 실행된다.
3) MANDATORY
이미 존재하는 트랜잭션을 지원하며, 진행중인 트랜잭션이 없으면 예외를 던진다.
4) REQUIRES_NEW :
항상 새로운 트랜잭션을 시작한다. 진행중인 트랜잭션이 있다면 해당 트랜잭션은 일시적으로 중단된다.
새로운 트랜잭션 안에서 예외가 발생해도 호출한 곳에는 롤백이 전파되지 않는다.
즉, 2개의 트랜잭션은 완전히 독립적인 별개로 단위로 작동한다.
5) NOT_SUPPORTED :
진행 중인 트랜잭션과 함께 실행할 수 없다.
항상 비트랜잭션으로 실행하고 기존 트랜잭션을 일시 중단한다.
6) NEVER :
진행중인 트랜잭션이 있더라도 항상 비트랜잭션으로 실행된다.
진행 중인 트랜잭션이 존재하는 경우엔 예외를 던진다.
7) NESTED :
진행 중인 트랜잭션이 있는경우 중첩 트랜잭션으로 실행된다.
진행중인 트랜잭션이 없으면 REQUIRED가 설정된 것처럼 실행된다.
중요한 차이점은, SAVEPOINT를 지정한 시점까지 부분 롤백이 가능하다는 것이다.
유의할 점은, 데이터베이스가 SAVEPOINT 기능을 지원해야 사용이 가능하다. (대표적으로 Oracle이 해당한다.
- 중첩 트랜잭션은 먼저 시작된 부모 트랜잭션의 커밋, 롤백 사항에 자식 트랜잭션이 영향을 받지만,
새로 생성된 자식 트랜잭션의 커밋과 롤백은 부모 트랜잭션에 영향을 주지 않는다.
5) 모놀로틱 아키텍처 서비스의 트랜잭션 관리
- 단일 DB의 트랜잭션 관리
기존의 모놀로틱 어플리케이션에서는 트랜잭션 관리가 쉽고 익숙하다.
일반적으로 개발자들은 트랜잭션 관리를 직접 코드로 구현하기 보다는,
트랜잭션 관리 기능들이 구현된 프레임워크 / 라이브러리를 사용하고,
그중에는 트랜잭션을 명시적으로 시작, 커밋, 롤백할 수 있는 프로그램형 API를 제공하는 제품도 있다.
예를 들어, 스프링 프레임워크는 AOP Proxy를 이용한 선언형 메커니즘을 제공한다.
예시 코드를 보면 아래와 같다.
@RequiredArgsConstructor
class AccountServiceImpl implements AccountService {
private final AccountRepository repository;
private final AccountEntityMapper mapper;
@Transactional
public void saveAccount(AccountCommand command) {
Account account = new Account(mapper.map(command));
repository.save(account);
}
// ...
// ...
}
이렇게 트랜잭션 단위로 수행되어야하는 메서드 선언부에 @Transactional 어노테이션을 달면,
해당 로직은 트랜잭션 안에서 실행되므로 편리하게 트랜잭션 관리를 수행할 수 있다.
* 스프링의 선언적 트랜잭션
스프링의 선언적 트랜잭션은 AOP(Aspect-oriented-programming)을 이용하고 있다.
개발자가 클래스나 메서드 레벨에 @Transactional을 작성하면,
스프링은 해당 빈 객체의 트랜잭션을 처리하기 위해 프록시 객체를 생성한다.
이 프록시 객체는 PlatformTransactionManager를 이용해서 트랜잭션을 시작한 뒤에,
실제 객체의 메서드를 호출하고,
그 다음에 PlatformTransactionManager를 이용해 트랜잭션을 커밋하거나
unchecked-exception(RuntimeException)이 발생 할 경우 롤백을 수행한다.
모든 비즈니스 메소드가 호출될때,
AOP를 사용해서 트랜잭션 블록을 시작하고,
메소드의 호출이 완료될 때, 트랜잭션을 커밋하거나 롤백할 수 있다.
아래의 예시 코드를 보면 한 눈에 이해하기 쉽다.
interface AccountService {
public void saveAccount(AccountCommand command);
// ...
// ...
}
class AccountServiceImpl implements AccountService {
private final AccountRepository repository;
private final AccountEntityMapper mapper;
@Transactional
public void saveAccount(AccountCommand command) {
Account account = new Account(mapper.map(command));
repository.save(account);
}
// ...
// ...
}
public class AccountProxy implements AccountService {
private final AccountService accountService;
private final TransactionManager transactionManager = TransactionManager.getInstance();
@Override
public void addAccount(AccountCommand command) {
try {
manager.begin();
accountService.addAccount(command); // 실제 사용자가 작성한 서비스의 비즈니스 메서드 호출
manager.commit();
} catch (RuntimeException e) {
// (checked-exception 발생시 롤백 X)
manager.rollback();
}
}
}
이러한 Proxy를 이용한다는 특징 때문에,
public 메서드에만 @Transactional 어노테이션이 설정 가능하고,
@Transactional 어노테이션이 달린 메서드에서 내부적으로 해당 클래스의 다른 메서드를 호출하면
내부 메서드의 경우에는 트랜잭션이 동작하지 않는다는 몇가지 제약사항이 있다.
추가로, Spring AOP 및
Spring에서 Proxy의 자세한 동작방식 (JDK Dynamic Proxy, CGLIB Proxy) 들이 있는데
요것까지 작성하기에는 본 글의 주제에서 살짝 벗어나기 때문에,
해당 주제의 포스팅으로 따로 작성해볼 예정이다.
이렇게 모놀로틱 어플리케이션에서 1개의 DB의 트랜잭션을 관리하려면,
개발자는 프레임워크 / 라이브러리에서 제공하는 트랜잭션 기능을 사용하면 되므로 매우 간단하다.
- 여러 서비스의 DB에 걸친 트랜잭션 관리
여러 개의 노드 또는 다른 종류의 데이터베이스가 참여하는 하나의 트랜잭션을
분산 트랜잭션(Distributed Transaction)이라고 한다.
여러 DB에 걸친 기능에 대해 트랜잭션을 관리하려면
좀 더 복잡한 분산 트랜잭션의 장치가 필요한데,
고전적인 방법으로는 분산 트랜잭션 관리의 사실상 표준인 X/Open DTP 모델 (XA)가 있다.
이 XA는 2단계 커밋 (2-Phase-Commit)을 이용하여
전체 트랜잭션 참여자가 반드시 커밋 아니면 롤백을 하도록 보장한다.
- XA의 분산 트랜잭션 과정
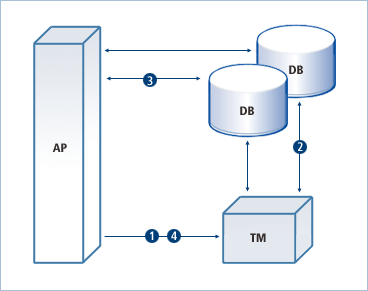
- 일반적으로 XA는 트랜잭션 매니저에 의해 코디네이트된다. 가장 먼저 애플리케이션은 TM에 분산 트랜잭션의 시작을 알린다.
- TM은 어떤 데이터베이스의 노드가 해당 분산 트랜잭션에 참여하는지 확인한다. 그 다음 각 데이터베이스 노드에 분산 트랜잭션의 시작을 알린다.
- 각 데이터베이스 노드에 분산 트랜잭션의 시작을 알릴 때 TM은 내부에 고유한 트랜잭션 ID를 만들어서 함께 전달한다.
그러면 각 데이터베이스 노드는 이 XID와 관련된 분산 트랜잭션을 시작한다.
앞으로 애플리케이션에서 들어오는 요청은 해당 분산 트랜잭션에 대한 작업이라고 인식한다. - 애플리케이션은 각 데이터베이스에 SQL 문장을 전달함으로써 필요한 작업을 진행한다.
- 이때 각 데이터베이스는 전달 받은 요청을 해당 XID와 관련된 작업이라고 인지하고 SQL 문장을 실행한다.
- 모든 작업이 완료되면 애플리케이션은 TM에 분산 트랜잭션의 종료를 알린다.
- TM은 해당 트랜잭션 ID로 분산 트랜잭션에 참여했던 각 데이터베이스 노드에 커밋과 롤백을 동시에 하도록 지시한다.
일부 데이터베이스는 커밋을 하고, 일부 데이터베이스는 롤백을 하는 상황이 벌어지지 않도록
TM은 Two-phase commit mechanism을 통해 수행한다.
- 2단계 커밋 메커니즘 (Two-phase commit mechanism)
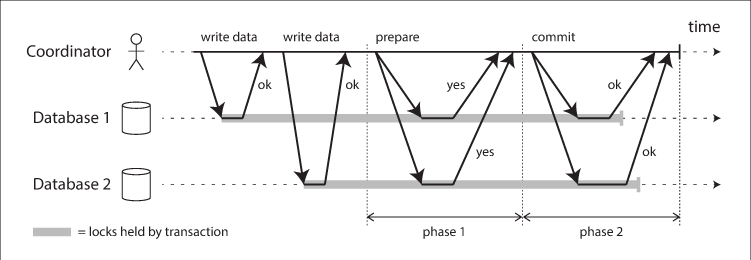
- First Phase(또는 Prepare Phase)다음은 First Phase가 실행되는 과정이다.
- TM은 각 데이터베이스 노드에 커밋을 준비하라는 prepare 메시지를 보낸다.
- 요청을 받은 각 데이터베이스는 커밋을 준비한다.
- 커밋을 하기 위한 준비 작업에는 필요한 리소스에 잠금(Lock)을 설정하거나 로그 파일을 저장하는 작업 등이 있다.
- 각 데이터베이스는 커밋 준비 여부에 따라 TM에 성공 또는 실패 여부를 알린다.
- 커밋 준비가 모두 끝나면 prepare가 성공한 것이고, 커밋 준비를 실패하면 prepare가 실패한 것이다.
- First Phase는 각 데이터베이스 노드에 커밋을 하기 위한 준비 요청 단계이다.
- TM은 참여한 모든 데이터베이스 노드로부터 prepare의 완료 메시지를 받을 때까지 대기한다.
Second Phase(또는 Commit Phase)이 단계에서는 전달 받은 prepare의 메시지에 따라 해당 결과가 다르다.
롤백 한 데이터베이스 노드라도 prepare ok 메시지를 받지 않으면 이 트랜잭션은 커밋할 수 없다고 판단하고, 모든 데이터베이스 노드에 롤백 메시지를 보내 해당 작업을 롤백한다. 커밋 모든 데이터베이스 노드로부터 prepare ok 메시지를 받으면 다시 모든 데이터베이스 노드에 커밋 메시지를 보내고 모든 작업을 커밋한다.
* 분산트랜잭션 기법 중 하나인
XA와 2 phase commit에 대한 내용은 본 포스팅의 주 내용은 아니므로,
아래에 출처를 밝히고 정리된 내용을 그대로 작성하였습니다.
제7장 분산 트랜잭션
하나의 데이터베이스 인스턴스 내에서 한 트랜잭션으로 묶인 SQL 문장이 모두 커밋되거나 롤백되듯이 네트워크로 연결된 여러 개의 데이터베이스 인스턴스가 참여하는 트랜잭션에서도 각각 다
technet.tmaxsoft.com
하지만 이러한 분산 트랜잭션은 간단해 보이지만 문제점이 많다.
일단 NoSQL DB (MongoDB, 카산드라)와 현대 메시지 브로커 (RabbitMQ, Apache Kafka)는
분산 트랜잭션을 지원하지 않기 때문에,
분산 트랜잭션이 필수라면 최근 기술은 상당수 포기해야 한다.
또한 분산 트랜잭션은 참여중인 서비스가 모두 가동 중이여야 커밋할 수 있기 때문에
가용성이 떨어진다는 문제점이 있다.
*가용성은 트랜잭션에 참여자의 가용성을 모두 곱한 값이다. 더 많은 서비스가 트랜잭션에 참여할 수록
가용성은 더 떨어지기 마련이다.
항상 개발 설계를 할 때 가용성과 일관성 사이의 트레이드 오프가 존재하지만,
요즘의 아키텍트들은 일관성보다 가용성을 우선시 하는 경향도 있다.
개발자 관점에서 분산 트랜잭션은 로컬 트랜잭션과 프로그래밍 모델이 동일하여
사용하기 편리하지만, 위와 같은 상당한 문제점들로 인해
MSA와 같은 요즘 애플리케이션의 구조와는 잘 맞지 않는다.
각 서비스들이 느슨하게 결합되어 비동기로 통신하는 구조를 토대로
분산 트랜잭션 대신 데이터 일관성을 유지할 수 있는 방법이 필요한데,
가장 대표적인 방법이 "사가 패턴"이다.
여기서부터는 2탄 주제로
마이크로서비스 아키텍처에서의 트랜잭션 관리를 주제로
별도의 포스팅을 작성할 예정이다!
여기까지 트랜잭션의 기본 개념, 특징, 격리 레벨과 전파 옵션,
그리고 Spring 프레임워크에서 주로 사용하는 선언적 트랜잭션과 분산 트랜잭션 내용을 다루어보았다.
참고:
https://m.yes24.com/Goods/Detail/86542732
마이크로서비스 패턴 - 예스24
모놀리식 애플리케이션을 마이크로서비스 아키텍처로 성공적으로 전환하는 방법마이크로서비스 아키텍처 기반의 애플리케이션을 성공적으로 구축하려면 새로운 아키텍처의 개념을 이해하는
m.yes24.com
'프로그래밍 > 기타' 카테고리의 다른 글
| [Spring] Aspected-Oriented Programming(AOP) 개념과 종류 정리 (0) | 2024.02.28 |
|---|---|
| [git] git rebase로 commit 정리하기 기록용 (1) | 2024.01.14 |
| [java] hashcode()와 equals() 메서드는 언제 사용하고 왜 사용할까? (4) | 2020.07.01 |
| [React] Nomad-coder 강의 React-Movie-App 완성 코드 분석 (0) | 2019.05.19 |





댓글 영역